Table des matières
- 16.1 Présentation de MySQL Cluster
- 16.2 Concepts de base de MySQL Cluster
- 16.3 Configuration simple multi-serveurs
- 16.4 Configuration de MySQL Cluster
- 16.5 Serveur de gestion du cluster MySQL
- 16.6 Administration de MySQL Cluster
- 16.7 Utilisation d'interconnexions haute vitesse avec MySQL Cluster
- 16.8 Cluster Limitations in MySQL 4.1
- 16.9 Cluster MySQL en 5.0 et 5.1
- 16.10 MySQL Cluster FAQ
- 16.11 MySQL Cluster Glossary
MySQL Cluster utiliser le nouveau moteur de table NDB
Cluster pour faire fonctionner plusieurs serveurs MySQL en
cluster. Le code du moteur NDB Cluster est
disponible dans le serveur BitKeeper de MySQL depuis la version
4.1.2 et avec les distribution binaires depuis MySQL-Max 4.1.3.
Actuellement, les systèmes d'exploitation supportés sont Linux,
Mac OS X et Solaris. Nous travaillons à rendre NDB
Cluster disponible sur toutes les plates-formes que
supporte MySQL, y compris Windows.
Ce chapitre est en cours de rédaction. Les autres documents decrivants le cluster MySQL sont disponibles à http://www.mysql.com/cluster et http://dev.mysql.com/doc.
Vous pouvez aussi vous inscrire sur le liste de diffusion du cluster MySQL. Voyez http://lists.mysql.com/.
Un Cluster MySQL est un groupe de processus qui s'exécutent sur
plusieurs serveurs MySQL, des noeuds
NDBCluster, et des processus d'administration,
ainsi que des processus d'accès spécialisés. Tous ces
programmes fonctionnent ensemble pour former un Cluster MySQL.
Lorsque les données sont stockées dans le moteur
NDBCluster, les tables sont réparties sur les
noeuds NDBCluster. Ces tables sont directement
accessibles depuis tous les autres serveurs MySQL faisant partie
du Cluster. Par conséquent, si une application met à jour une
ligne, tous les autres serveurs le verront immédiatement.
Les données stockées dans le moteur de table de MySQL Cluster peut être dupliquées, et sont capables de gérer une indisponibilité d'un noeud sans autre impact que l'annulation des transactions qui utilisaient ces données. Cela ne devrait pas être un problème, cas les applications transactionnelles sont écrites pour gérer les échecs de transaction.
En pla¸ant MySQL Cluster en Open Source, MySQL rend les hautes performances, haute disponibilité et grands trafics accessibles à tous ceux qui en ont besoin.
MySQL Cluster est constitué de trois types de programmes différents :
Premièrement, un jeu de processus serveurs MySQL. Ce sont des serveurs MySQL traditionnelles, avec le nouveau moteur de table
NDBClusterqui autorise l'accès aux tables en cluster.Le second type de processus est représenté par les noeuds de stockage de
NDBCluster. Ces processus contiennent les données stockées dans MySQL Cluster. Les données de MySQL Cluster sont réparties entre les différents noeuds du cluster, et sont aussi doublées dans le cluster.Le troisième type de processus est les processus d'administration. Ces processus sont utilisées pour gérer la configuration du cluster.
Nous appelons ces processus de cluster les noeuds du cluster. Mettre en place la configuration du cluster implique la configuration de chaque noeud dans le cluster, et la configuration de chaque moyen de communication entre les noeuds du cluster. MySQL Cluster est actuellement configuré avec le pré-requis que les noeuds sont homogènes en terme de puissance processeur, espace mémoire et largeur de bande. De plus, pour activer un point de configuration, il a été décidé de placer toute la configuration du cluster dans un seul fichier de configuration.
Les processus d'administration gère le fichier de configuration du cluster, et les logs. Tous les noeuds dans le cluster contactent le serveur d'administration pour lire leur configuration : ils doivent donc savoir où le serveur d'administration réside en premier lieu. Lorsqu'un événement pertinent survient dans un moteur de stockage, il est transféré au serveur d'administration qui l'écrit dans le log.
De plus, il y a un nombre arbitraire de clients connectés au cluster. Ils sont de deux types. D'abord, les clients MySQL normaux, qui ne sont pas spécifiques à MySQL Cluster. MySQL Cluster est accessible à partir des applications MySQL écrites en PHP, Perl, C, C++, Java, Ruby, etc. Deuxièmement, les clients d'administration. Ces clients accèdent au serveur d'administration, et émettent des commandes pour lancer ou arrêter correctement des noeuds, lancer ou arrêter la trace serveur (pour les versions de débogage), pour afficher la configuration courante, voir l'état des noeuds du cluster, afficher les versions et noeuds, lancer les sauvegardes, etc.
Cette section est un guide qui décrit comment planifier l'installation, configurer et faire fonctionner un cluster MySQL viable. Contrairement aux exemples de la section Section 16.4, « Configuration de MySQL Cluster », le résultat de ces procédures est un cluster MySQL fonctionnel, qui dispose des fonctionnalités minimale pour assurer la disponibilité et la sauvegarde des données.
Dans cette section, nous allons couvrir : le matériel et les logiciels nécessaires; les problèmes réseau; l'installation de MySQL et du cluster; la configuration; le démarrage, l'arrêt et le redémarrage du cluster MySQL; le chargement de données dans une base d'exemple; l'exécution de requêtes.
Hypothèses de base
Ce guide part des hypothèses suivantes :
Nous allons configurer un clusteur de quatre noeuds, chacun sur un hôte distinct, et chacun des hôtes étant relié au réseau avec une adresse IP fixe, via une carte Ethernet classique, comme ceci :
Noeud Adresse IP Noeud de gestion (MGM) 192.168.0.10 Serveur MySQL (SQL) 192.168.0.20 Serveur de stockage (NDBD) "A" 192.168.0.30 Serveur de stockage (NDBD) "B" 192.168.0.40 Cela est peut-être plus clair sur le schéma suivant :
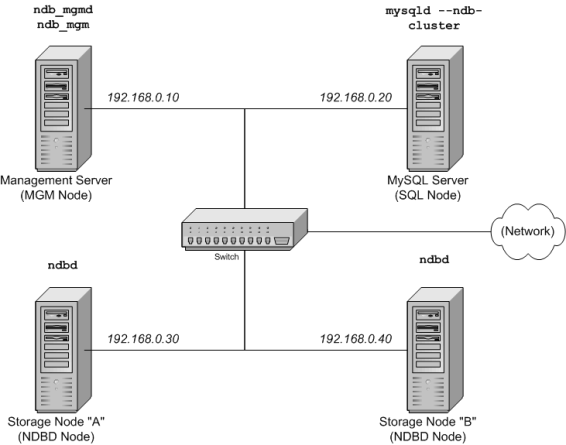
Note : par souci de simplicity et de robustesse, nous allons utiliser les adresses IP numériques dans ce guide. Cependant, si la résolution DNS est disponible sur votre réseau, il est aussi possible d'utiliser les noms d'hôtes plutôt que les IP lors de la configuration du cluster. Alternativement, vous pouvez aussi utiliser le fichier
/etc/hostsde votre système d'exploitation ou son équivalent pour fournir un système de résolution de noms.Chaque hôte est un ordinateur de bureau Intel, avec une distribution générique LInux sur le disque, dans une configuration standard, et sans aucun service inutile. Le coeur du système et une client standard TCP / IP doivent être suffisants. De même, par souci de simplicité, nous allons suppposer que les systèmes de fichiers des hôtes sont tous identiques. Dans le cas où il ne le sont pas, vous devrez adapter les instructions en fonctions des situations.
Des cartes 100 megabits ou gigabits Ethernet sont installées sur chaque machine, avec les bons pilotes pour les cartes, et chaque hôte est connecté au réseau via un routeur standard, comme un switch. Toutes les machines doivent utiliser des cartes avec le même débit, c'est à dire que toutes les machines du cluster sont en 100 megabits, or bien en gigabit. Le cluster MySQL fonctionnera sur un réseau 100 megabits, mais les cartes gigabit fourniront de meilleures performances.
Notez que le cluster MySQL n'est pas prévu pour fonctionner sur un réseau avec une connectivité inférieure à 100 megabits. Pour cette raison, entre autres, faire fonctionner un cluster MySQL sur un réseau public ou via Internet risque de ne pas réussier, et n'est pas recommandé.
Pour les données de tests, nous allons utiliser la base de données world qui est disponible en téléchargement sur le site de MySQL AB. Comme cette base de données prend peut d'espace, nous pouvons fonctionner avec des machines ayant 256 Mo de RAM, ce qui doit être suffisant pour le système d'exploitation, les processus NDB et le stockage dans les noeuds.
Même si nous faisons référence à Linux comme système d'exploitation dans ce guide, les instructions et les procédures sont faciles à adapter pour Solaris ou Mac OS X. Nous supposons aussi que vous savez faire une installation minimale et la configuration du système d'exploitation en réseau, ou que vous disposez d'assistance pour ce faire.
Nous allons présenter les besoins en matériel, logiciels et réseau pour le cluster MySQL dans la prochaine section. Voyez Section 16.3.1, « Matériel, logiciels et réseau ».
Une des forces du Cluster MySQL est qu'il
peut fonctionner sur n'importe quel serveur, et n'a pas de
prérequis particulier, en dehors d'une grande quantité de
mémoire vive, due au fait que toutes les données sont
stockées en mémoire. Notez que cela pourrait changer à
l'avenir, et que nous travaillons à avoir un stockage sur
disque dans les prochaines versions du Cluster
MySQL. Naturellement, les machines multi-processeurs
et celles aux fréquences supérieures seront plus rapides. Les
besoins en RAM des processus du Cluster MySQL
sont relativement raisonnables.
Les besoins en logiciels pour le Cluster
MySQL sont aussi modestes. Les systèmes
d'exploitation hôtes n'ont pas besoin de modules particuliers,
ni services, ni applications ou configurations pour supporter
Cluster MySQL. Pour Mac OS X ou Solaris,
l'installation standard est suffisante. Pour Linux, une
installation standard de base doit être suffisante. Les
prérequis pour MySQL sont simples : tout ce qui est
nécessaire pour faire fonctionner MySQL-max
4.1.3 ou plus récent; vous devez utiliser la version
-max de MySQL pour avoir le support du
Cluster MySQL. Il n'est pas nécessaire de
compiler MySQL vous-même pour être en mesure d'exécuter le
Cluster MySQL. Dans cette documentation, nous
allons supposer que vous utilisez le binaire
-max adapté à votre système, disponible
via la page de téléchargements de MySQL :
http://dev.mysql.com/downloads.
Pour les communication entre les noeuds, Cluster
MySQL supporte le protocole TCP/IP pour toutes les
topologies, et le minimum attendu pour chaque hôte est une
carte Ethernet 100 megabits, plus un switch, hub ou routeur pour
fournir la connectivité entre les parties du Cluster. Nous
recommandons vivement que le Cluster MySQL
dispose de son propre masque de sous-réseau pour les raisons
suivantes :
Sécurité : les communications entre les noeuds du
Cluster MySQLne sont pas chiffrées ou protégées de quelque manière que ce soit. La seule solution pour protéger les transmissions à l'intérieur duCluster MySQLest de placer leCluster MySQLdans un réseau protégé. Si vous envisagez d'utiliser leCluster MySQLpour une application Web, il est recommandé que leCluster MySQLsoit placé derrière un pare-feu, et non pas dans la zone démilitarisée (DMZ) ou ailleurs.Efficacité : configurer un
Cluster MySQLsur un réseau privé ou protégé donne auCluster MySQLl'exclusivité de la bande passante. En utilisant un switch dédié auCluster MySQLaide à la protection contre les accès non autorisés, et il protège les noeuds des interférences causées par les autres machines sur le réseau. Pour une stabilité accrue, vous pouvez utiliser des switchs redondants et des cartes réseau doubles pour supprimer du réseau les points de panne : de nombreux pilotes réseau savent s'adapter si une panne survient sur un brin de réseau.
Il est aussi possible d'utiliser l'interface SCI
(Scalable Coherent Interface à haute
vitesse, avec le Cluster MySQL, mais ce n'est
pas nécessaire. Voyez
Section 16.7, « Utilisation d'interconnexions haute vitesse avec MySQL Cluster » pour plus
d'informations sur ce protocole et ses utilisation avec
Cluster MySQL.
Chaque hôte du cluster MySQL qui héberge un noeud de stockage ou un noeud SQL doit être installé avec MySQL-max. Pour les noeuds de gestion, il n'est pas nécessaire d'installer un serveur MySQL, mais vous devez installer un démon MGM et les clients ndb_mgmd et ndb_mgm, respectivement. Dans cette section, nous allons voir les étapes nécessaires pour installer correctement chaque serveur pour un noeud du cluster.
Au moment de l'écriture de cette section, les versions les plus
récentes étaient MySQL 4.1.10a; si une version plus récente
est dinsponible, il est recommandée de l'installer et
d'utiliser ce numéro de version dans tout le reste de la
section. MySQL fournit des serveurs précompilés, et il n'y a
généralement pas besoin de compiler par vous-même. Si vous
voulez faire une compilation personnalisée, voyez
Section 2.4.3, « Installer à partir de l'arbre source de développement ». Par conséquent, la
première étape de l'installation de chaque hôte du cluster
est de télécharger le fichier
mysql-max-4.1.10a-pc-linux-gnu-i686.tar.gz
depuis MySQL
downloads area. Nous supposons que vous l'avez fait, et
installé dans le dossier /var/tmp de
chaque machine.
Des RPM sont aussi disponibles pour les plate-formes 32 et 62
bits; depuis MySQL 4.1.10a, les serveurs
MySQL-max installés via RPM supportent les
clusters NDB. Si vous choisissez d'utiliser ces outils plutôt
que les fichiers binaires, assurez-vous d'installer
à la fois les paquets
-server et -max sur toutes
les machines qui hébergent des noeuds du cluster. Voyez
Linux pour plus d'informations sur
l'installation de MySQL en RPM. Après l'installation des RPM,
nous devez toujours configurer le cluster, tel que présenté
dans Section 16.3.3, « Configuration ».
Note! : après l'installation, ne lancez pas encore les logiciels. Nous allons vous montrer comment le faire, alors suivez d'abord la configuration des noeuds.
Installation des noeuds de stockage et SQL
Pour chacune des machines désignées pour être des hôtes de stockage ou des hôtes SQL, suivez les étapes suivantes, en tant que super utilisateur :
Vérifiez vos fichiers
/etc/passwdet/etc/groupou utilisez les outils systèmes dont vous disposez pour gérer les groupes et utilisateurs pour vérifier si vous avez un groupemysqlet un utilisateurmysqlsur votre système : certaines distributions les créent automatiquement lors de leur installation. Si ces comptes n'existent pas, alors créez un groupemysqlet un utilisateurmysql, comme ceci :groupadd mysql useradd -g mysql mysql
Placez-vous dans le dossier qui contient le fichier téléchargé; décompressez l'archive; créez un lien symbolique vers l'exécutable
mysql-max:cd /var/tmp tar -xzvf -C /usr/local/bin mysql-max-4.1.10a-pc-linux-gnu-i686.tar.gz ln -s /usr/local/bin/mysql-max-4.1.10a-pc-linux-gnu-i686 mysql
Placez vous dans le dossier
mysql, et exécutez le script fournit pour la création des bases de données système :cd mysql scripts/mysql_install_db --user=mysql
Donnez les droits nécessaires au serveur MySQL et au dossier de données :
chown -R root . chown -R mysql data chgrp -R mysql .
Notez que le dossier de données de chaque machine qui héberge un noeud de stockage est
/usr/local/mysql/data. Nous allons utiliser cette information lors de la configuration du noeud de gestion. Voyez Section 16.3.3, « Configuration ».Copiez le script de démarrage MySQL dans le dossier approprié, rendez-le exécutable, et configurez-le pour qu'il s'exécute lorsque le système d'exploitation démarre :
cp support-files/mysql.server /etc/rc.d/init.d/ chmod +x /etc/rc.d/init.d/mysql.server chkconfig --add mysql.server
Ici, nous utilisons la commande de Red Hat chkconfig pour créer les liens vers les scripts de démarrage; utilisez les moyens appropriés pour faire la même chose sur votre système d'exploitation, tel que update-rc.d sur Debian.
N'oubliez pas que ces listes d'instructions doivent être exécutées séparéement sur chaque machine qui sera un noeud de stockage ou un noeud SQL.
Installation du noeud de gestion
Pour le noeud MGM (serveur de gestion), il n'est pas nécessaire
d'installer mysqld, mais seulement le serveur
MGM et les clients, qui sont disponibles dans l'archive
-max. Encore une fois, nous supposons que
vous avez placé de fichier dans le dossier
/var/tmp. En tant que root (c'est à dire,
après avoir exécuté la commande su root ou
l'équivalent sur votre système pour se faire attribuer les
droits de super utilisateur), effectuez les commandes suivantes
pour installer ndb_mgmd et
ndb_mgm sur l'hôte de gestion :
Allez dans le dossier
/var/tmpet décompressez ndb_mgm et ndb_mgmd de l'archive, dans un dossier approprié, comme/usr/local/bin:cd /var/tmp tar -zxvf mysql-max-4.1.10a-pc-linux-gnu-i686.tar.gz /usr/local/bin '*/bin/ndb_mgm*'
Placez-vous dans le dossier où vous avez décompressé les fichiers, puis rendez-les tous les deux exécutables :
cd /usr/local/bin chmod +x ndb_mgm*
Dans Section 16.3.3, « Configuration », nous allons créer et configurer les fichiers pour tous les noeuds du cluster d'exemple.
Pour notre MySQL Cluster de quatre noeuds et
quatre hôtes, nous auront besoin de préparer quatres fichiers
de configuration, un par hôte/noeud.
Chaque noeud de stockage ou noeud SQL a besoin d'un fichier
my.cnfqui fournit 2 informations : une chaîne connectstring qui indique au noeud où trouver le noeud MGM, et une ligne indiquant au serveur MySQL de cet hôte de fonctionner en mode NDB.Pour plus d'informations sur les chaînes de connexion, voyez Section 16.4.4.2, « La chaîne
connectstringdu Cluster MySQL ».Le noeud degestion a besoin d'un fichier
config.iniqui indique combien de réquliques doivent être gérées, combien de mémoire allouer pour les données et les index sur chaque noeud de stockage, où trouver les noeuds de stockage, où les données seront sauvées sur le disque, et où trouver les noeuds SQL.
Configurer les noeuds de stockage et SQL
Le fichier my.cnf destiné aux noeuds de
stockage est plutôt simple. Le fichier de configuration doivent
être placé dans le dossier /etc et peut
être édiét ou créé avec n'importe quel éditeur fichier.
Par exemple :
vi /etc/my.cnf
Pour chaque noeud de stockage et chaque noeud SQL de notre
exemple, le fichier my.cnf doit ressembler
à ceci :
[MYSQLD] # Options du processus mysqld ndbcluster # Fonctionne en mode NDB ndb-connectstring=192.168.0.10 # Situation du noeud MGM [MYSQL_CLUSTER] # Options pour le processus ndbd ndb-connectstring=192.168.0.10 # Situation du noeud MGM
Après la saisie des données ci-dessus, sauvez ce fichier et quittez l'éditeur de texte. Faites cela pour les noeuds de stockages "A" et "B", et le noeud SQL.
Configuration du noeud de gestion
La première étape de configuration du noeud MGM est la création du dossier dans lequel le fichier de configuration sera placé, et d'y créer le fichier lui-même. Par exemple, lors d'un fonctionnement root :
mkdir /var/lib/mysql-cluster cd /var/lib/mysql-cluster vi config.ini
Nous présentons ici la commande vi utilisée pour créer le fichier, mais n'importe quel autre éditeur texte fonctionnement aussi bien.
Pour notre configuration d'exemple,
config.ini doit contenir les informations
suivantes :
[NDBD DEFAULT] # Options affectant les processus ndbd processes sur tous les noeuds
NoOfReplicas=2 # Nombre de répliques
DataMemory=80M # Mémoire à allouer pour le stockage des données
IndexMemory=52M # Mémoire à allouer pour le stockage des index
# Pour DataMemory et IndexMemory, nous avons utilisé les
# valeurs par défault. Comme la base de données "world"
# ne prend que 500KB, cela devrait être suffisant pour notre
# exemple de Cluster
[TCP DEFAULT] # Options TCP/IP
portnumber=2202 # Ceci est la valeur par défaut. Cependant, nous pourrions
# utiliser un port libre pour les autres hôtes du cluster.
# Note : il est recommandé avec MySQL 5.0 de ne pas spécifier
# de port, et de laisser la valeur par défaut.
[NDB_MGMD] # Options de gestion des processus :
hostname=192.168.0.10 # Nom d'hôte ou adresse IP du noeud MGM
datadir=/var/lib/mysql-cluster # Dossier des fichiers de logs du noeud MGM
[NDBD] # Options pour le stockage du noeud "A" :
# (une section [NDBD] par noeud de stockage)
hostname=192.168.0.30 # Nom d'hôte ou adresse IP
datadir=/usr/local/mysql/data # Dossier pour les fichiers de données du noeud
[NDBD] # Options pour le stockage du noeud "B" :
hostname=192.168.0.40 # Nom d'hôte ou adresse IP
datadir=/usr/local/mysql/data # Dossier pour les fichiers de données du noeud
[MYSQLD] # Options des noeuds SQL :
hostname=192.168.0.20 # Nom d'hôte ou adresse IP
# (Les connexions mysqld supplémentaires peuvent
# être spécifiées pour ce noeud pour différents
# objectifs, comme l'exécution de ndb_restore)
NOTE : la base de données
"world" peut être téléchargée sur le site
http://dev.mysql.com/doc/,
rangé dans la section d'exemples : Examples.
Une fois que tous les fichiers de configuration ont été créés et que ces options minimales ont été spécifiées, vous êtes prêts à lancer le cluster MySQL et à vérifier que les processus fonctionnent. La présentation de cette étape est faîte dans Section 16.3.4, « Démarrage initial ».
Pour plus de détails sur les paramètres de configuration du cluster MySQL, voyez Section 16.4.4, « Fichier de configuration » et Section 16.4, « Configuration de MySQL Cluster ». Pour la configuration du Cluster MySQL au sujet des sauvegardes, voyez Section 16.6.4.4, « Configuration pour la sauvegarde du Cluster ».
Note : le port par défaut pour le noeud de gestion du Cluster MySQL est le 1186; le port par défaut pour les noeuds de stockage est 2202.
Démarrer le cluster n'est pas très difficile une fois qu'il a été configuré. Chaque noeud doit être lancé séparément, et depuis l'hôte sur lequel il réside. Même s'il est possible de lancer les noeuds dans n'importe quel ordre, il est recommandé de lancer le serveur d'administration en premier, puis les noeuds de stockage et enfin, les noeuds SQL :
Sur l'hôte de gestion, utilisez la commande suivante depuis le Shell pour lancer le processus de gestion :
shell> ndb_mgmd -f /var/lib/mysql-cluster/config.ini
Notez que ndb_mgmd doit recevoir le nom et chemin du fichier de configuration, avec l'option
-fou--config-file. Voyez Section 16.5.3, « ndb_mgmd, le serveur de gestion » pour plus de détails.Sur chaque hôte de stockage, exécutez cette commande pour lancer les processus NDBD :
shell> ndbd --initial
Notez qu'il est très important d'utiliser le paramètre
--initialuniquement lors du premier démarrage de ndbd, ou lors du redémarrage apràs une opération de restauration des données ou de modification de configuration. En effet, ce paramètre va forcer le noeud à effacer les fichiers créé par les anciennes instances de ndbd, y compris les fichiers de log.Sur les hôtes SQL, exécutez une commande mysqld classique :
shell> mysqld &
Si tout se passe bien, et que le cluster a été correctement configuré, il devrait être opérationnel à nouveau. Vous pouvez tester cela en utilisant la commande ndb_mgm, c'est à dire le client de gestion; le résultat devrait être similaire à celui-ci :
shell> ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm> show
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.30 (Version: 4.1.11, Nodegroup: 0, Master)
id=3 @192.168.0.40 (Version: 4.1.11, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.10 (Version: 4.1.11)
[mysqld(SQL)] 1 node(s)
id=4 (Version: 4.1.11)
Vous pouvez rencontrer diverses adaptations en fonction des versions exactes de MySQL que vous utilisez.
Note : si vous utilisez une
ancienne version de MySQL, vous pourriez voir les noeuds SQL
référencés sous le nom
‘[mysqld(API)]’. C'est une
ancienne pratique qui n'a plus court.
Vous êtes maintenant prêts à utiliser vos bases de données, vos tables et vos données dans le cluster MySQL. Voyez Section 16.3.5, « Charger les données d'exemple et exécuter des requêtes » pour aller plus loin.
Travailler avec le cluster MySQL n'est pas différent de travailler avec un serveur MySQL classique. Il y a deux points importants à garder en tête :
Les tables doivent être créées avec le moteur
ENGINE=NDBouENGINE=NDBCLUSTER, ou doivent être modifiée avecALTER TABLEpour qu'elles utilisent le moteur NDB, afin qu'elles soivent gérées par le cluster. Si vous importez des tables depuis une base de données existante en utilisant le résultat de mysqldump, vous pouvez ouvrir le script SQL dans un éditeur de texte, et ajoutez cette option à toutes les créations de tables, ou bien remplacez les optionsENGINEouTYPE) avec l'une des valeurs ci-dessous. Par exemple, en supposant que vous utilisez la base world dans un autre serveur MySQL, qui ne supporte pas le cluster MySQL, et que vous voulez exporter la définition de la tableCITY:shell> mysqldump --add-drop-table world City > city_table.sql
Le résultat du fichier
city_table.sqlcontient la commande de création de la table et les commandes d'insertionINSERTpour importer les données dans la table :DROP TABLE IF EXISTS City; CREATE TABLE City ( ID int(11) NOT NULL auto_increment, Name char(35) NOT NULL default '', CountryCode char(3) NOT NULL default '', District char(20) NOT NULL default '', Population int(11) NOT NULL default '0', PRIMARY KEY (ID) ) TYPE=MyISAM; INSERT INTO City VALUES (1,'Kabul','AFG','Kabol',1780000); INSERT INTO City VALUES (2,'Qandahar','AFG','Qandahar',237500); INSERT INTO City VALUES (3,'Herat','AFG','Herat',186800); # (remaining INSERT statements omitted)
Vous devez vous assurer que MySQL utilise le moteur NBD pour cette table. Il y a deux moyens pour le faire. L'un deux, avant l'importation des données dans la table, consiste à modifier la définition de la table pour qu'elle corresponde à ceci (toujours en utilisant la table City) :
DROP TABLE IF EXISTS City; CREATE TABLE City ( ID int(11) NOT NULL auto_increment, Name char(35) NOT NULL default '', CountryCode char(3) NOT NULL default '', District char(20) NOT NULL default '', Population int(11) NOT NULL default '0', PRIMARY KEY (ID) ) ENGINE=NDBCLUSTER; INSERT INTO City VALUES (1,'Kabul','AFG','Kabol',1780000); INSERT INTO City VALUES (2,'Qandahar','AFG','Qandahar',237500); INSERT INTO City VALUES (3,'Herat','AFG','Herat',186800); # (etc.)
Cela doit être fait pour la définition de chaque table qui fait partie de la base de données en cluster. Le plus simple pour faire cela est de faire un rechercher-remplacer dans le fichier
world.sqlet de remplacer toutes les instances deTYPE=MyISAMparENGINE=NDBCLUSTER. Si vous ne voulez pas modifier ce fichier, vous pouvez aussi utiliser la commandeALTER TABLE; voyez plus bas pour les spécificités.En supposant que vous ave déjà créé la base de données appelée world sur le noeud SQL du cluster, vous pouvez utiliser l'utilitaire de ligne de commande mysql pour lire le fichier
city_table.sql, et créer puis remplir la table, comme ceci :shell> mysql world < city_table.sql
Il est très important de garder en tête que lest commandes ci-dessus doivent être exécutées sur l'hôte où le noeud SQL tourne : dans ce cas, sur la machine avec l'adresse IP 192.168.0.20.
Pour créer une copie de la base de données world sur le noeud SQL, sauvez le fichier dans
/usr/local/mysql/data, puis exécutez ces commandes :shell> cd /usr/local/mysql/data shell> mysql world < world.sql
Bien sur, le script SQL doit être lisible par l'utilisateur mysql. Si vous sauvez le fichier à un autre endroit, ajustez les chemins dans les commandes ci-dessus.
Exécuter les commandes SELECT sur un noeud SQL n'est pas différent de les exécuter sur une autre instance de serveur MySQL. Pour exécuter les requêtes SQL en ligne de commande, vous devez vous identifier sur le serveur, comme d'habitude :
shell> mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 to server version: 4.1.9-max Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>
Si vous n'avez pas modifié les clauses
ENGINE=dans les définitions de tables, vous pouvez alors utiliser ces commandes :mysql> USE world; mysql> ALTER TABLE City ENGINE=NDBCLUSTER; mysql> ALTER TABLE Country ENGINE=NDBCLUSTER; mysql> ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
Notez que nous avons simplement utilisé le compte d'administrateur par défaut, sans mot de passe. Bien entendu, dans un environnement de production, il est recommandé de toujours suivre les précautions de sécurité, y compris l'utilisation d'un mot de passe robuste pour le super utilisateur, et la création d'un compte spécifique, avec uniquement les droits nécessaires aux tâches incombantes. Pour plus de détails, voyez la section Section 5.5, « Règles de sécurité et droits d'accès au serveur MySQL ».
Il est à noter que les noeuds du cluster n'utilisent pas les droits d'accès MySQL lorsqu'ils se connectent l'un à l'autre : modifier ces droits n'a pas d'effet sur les communications entre les noeuds.
Sélectionner la base de donées et exécuter une requête
SELECTsur une table se fait comme d'habitude :mysql> USE world; mysql> SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5; +-----------+------------+ | Name | Population | +-----------+------------+ | Bombay | 10500000 | | Seoul | 9981619 | | São Paulo | 9968485 | | Shanghai | 9696300 | | Jakarta | 9604900 | +-----------+------------+ 5 rows in set (0.34 sec) mysql> \q Bye shell>
Les applications qui reposent sur MySQL peuvent utiliser l'API standard. Il est important de penser à ce que votre application doit se connecter à un noeud SQL, et non pas aux noeuds de stockage ou au serveur de gestion. Cet exemple montre comment vous ourriez exécuter une requête en utilisant l'extension
mysqlide PHP 5, sur un serveur Web :<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"> <title>Sélection de données avec mysqli</title> </head> <body> <?php # Connexion au noeud SQL : $link = new mysqli('192.168.0.20', 'root', '', 'world'); # Les paramètres pour le constructeur mysqli sont : # hote, utilisateur, mot de passe, base de données if( mysqli_connect_errno() ) { die("Connexion échouée : " . mysqli_connect_error()); } $query = "SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5"; # s'il n'y a pas d'erreur if( $result = $link->query($query) ) { ?> <table border="1" width="40%" cellpadding="4" cellspacing ="1"> <tbody> <tr> <th width="10%">Ville</th> <th>Population</th> </tr> <?php // Affichage du résultat while($row = $result->fetch_object()) printf(<tr>\n <td align=\"center\">%s</td><td>%d</td>\n</tr>\n", $row->Name, $row->Population); ?> </tbody </table> <?php // Vérification du nombre de ligne lues printf("<p>Lignes affectées : %d</p>\n", $link->affected_rows); } else # Sinon, affichage de l'erreur echo mysqli_error(); // Libération du résultat et de l'objet de connexion $result->close(); $link->close(); ?> </body> </html>Nous supposons que le processus du serveur Web peut atteindre l'IP du noeud SQL.
De manière similaire, vous pouvez utiliser l'API C de MySQL, ou les interface Perl-DBI, Python-mysql ou encore les connecteurs de MySQL AB pour effectuer les tâches de définition de données et de manipulations, comme vous le faîtes habituellement avec un serveur MySQL.
N'oubliez pas que toutes les tables NDB doivent avoir une clé primaire. Si aucune clé primaire n'est définie par l'utilisateur lors de la création de la table, le moteur de stockage NDB va en générer une automatiquement. Note : cette clé caché prend de l'espace, comme tout autre indexe. Il n'est pas rare de rencontrer des problèmes de mémoire lorsque vous devez prendre en compte ces clés automatiques.
Pour arrêter le cluster, utilisez simplement cette commande dans le Shell sur la machine qui héberge le serveur de gestion MGM :
shell> ndb_mgm -e shutdown
Cela va forcer les processus ndb_mgm, ndb_mgm et ndbd à s'arrêter proprement. Tous les noeuds SQL peuvent alors être arrêté avec la commande mysqladmin shutdown classiques ou par d'autres moyens.
Pour relancer le cluster, lancez simplement ces commandes :
Sur l'hôte de gestion (192.168.0.10 dans notre cas) :
shell> ndb_mgmd -f /var/lib/mysql-cluster/config.ini
Sur chaque noeud de stockage (192.168.0.30 et 192.168.0.40) :
shell> ndbd
N'oubliez pas d'invoquer cette commande avec l'option
--initiallorsque vous redémarrez un noeud NDBD normalement.Et les hôtes SQL (192.168.0.20) :
shell> mysqld &
Pour des informations sur les sauvegardes, voyez Section 16.6.4.2, « Utilisation du serveur de gestion pour une sauvegarde de cluster ».
Pour restaurer le cluster à partir de sauvegardes, il faut utiliser la commande ndb_restore. Vous pouvez vous informer la dessus sur Section 16.6.4.3, « Comment restaurer une sauvegarde du cluster ».
Plus d'information sur la configuration du cluster MySQL est disponible dans Section 16.4, « Configuration de MySQL Cluster ».
Un serveur MySQL est une partie d'un cluster MySQL, et il ne
diffère d'un serveur classique que d'un seul aspect : il dispose
d'un moteur de stockage supplémentaire, à savoir :
NDB ou NDBCLUSTER.
A part cela, le serveur MySQL n'est pas très différent de ceux
que nous utilisons traditionnellement. Par défaut, le serveur est
configuré sans le moteur NDB (pour éviter
d'allouer des ressources inutiles). Pour activer
NDB, vous deve modifier
my.cnf.
De plus, comme le serveur MySQL est une partie du cluster, il doit
savoir comment accéder au noeud MGM, pour connaître la
configuration du cluster. Il y a un comportement par défaut qui
recherche le noeud MGM sur le serveur local. Mais si vous devez le
placer ailleurs, vous pouvez le en ligne de commande ou bien dans
le fichier my.cnf. Avant que le moteur de
stockage NDB ne soit utilisé, un noeud MGM est
une base de noeud doit être active et accessible. Le seul noeud
MGM est suffisant pour démarrer.
NDB Cluster est disponible en distribution
binaire depuis MySQL-Max 4.1.3.
Si vous décidez de compiler le cluster depuis les sources ou
depuis MySQL 4.1 BitKeeper, assurez-vous d'utiliser l'option
--with-ndbcluster avec la commande
configure.
Vous pouvez aussi utiliser simplement le script
BUILD/compile-pentium-max. Ce script inclut
aussi OpenSSL, ce qui vous impose d'avoir OpenSSL installé ou
de modifier le script de compilation pour l'exclure.
A part cela, vous pouvez suivre les instructions standard de compilation pour créer vos propres programmes, effectuer les tests et l'installation. See Section 2.4.3, « Installer à partir de l'arbre source de développement ».
Il est plus facile de faire l'installation si vous avez déjà
installé les serveurs de gestion (MGM) et
les noeuds de bases (DB), et qu'ils sont
actifs : cela sera surement la partie la plus longue de
l'installation, en supposant que vous êtes déjà maître de
MySQL. Comme pour les fichiers de configuration et
my.cnf, la structure du fichier est très
claire, et cette section ne couvre que les différences
spécifiques du cluster, par rapport à MySQL classique.
Cette section montre comment configurer rapidement puis démarrer l'architecture la plus simple d'un cluster MySQL. Vous serez alors familiers avec les concepts de base. Puis, lisez les autres sections pour adapter plus finement votre installation.
Un dossier doit être créé. L'exemple utilise
/var/lib/mysql-cluster. Exécutez la
commande suivante, en tant que root:
shell> mkdir /var/lib/mysql-cluster
Dans ce dossier, créez un fichier
config.ini avec le contenu suivant.
Remplacez HostName et
DataDir par les valeurs de votre
installation.
# file "config.ini" - showing minimal setup consisting of 1 DB node, # 1 management server, and 3 MySQL servers. # The empty default sections are not needed, and are shown only for clarity. # Storage nodes are required to provide a host name but MySQL Servers # are not. Thus the configuration can be dynamic as to setting up the # MySQL Servers. # If you don't know the host name of your machine, use localhost. # The DataDir parameter also has a default value, but it is recommended to # set it explicitly. # NDBD, MYSQLD, and NDB_MGMD are aliases for DB, API, and MGM respectively # [NDBD DEFAULT] NoOfReplicas= 1 [MYSQLD DEFAULT] [NDB_MGMD DEFAULT] [TCP DEFAULT] [NDB_MGMD] HostName= myhost.example.com [NDBD] HostName= myhost.example.com DataDir= /var/lib/mysql-cluster [MYSQLD] [MYSQLD] [MYSQLD]
Vous pouvez maintenant lancer le serveur de gestion. Pour cela, faites :
shell>cd /var/lib/mysql-clustershell>ndb_mgmd
Puis, lancez un noeud de base, grâce au programme
ndbd. Si c'est la toute première fois que
vous lancez ndbd, utilisez l'option
--initial :
shell> ndbd --initial
Lors des prochains appels à ndbd, ne l'utilisez plus.
shell> ndbd
Par défaut, ndbd va rechercher le serveur de
gestion sur localhost, port 2200.
Notez que si vous avez installé une distribution binaire, vous
aurez besoin de spécifier explicitement le chemin des commandes
ndb_mgmd et ndbd. Ils se
trouvent dans le dossier
/usr/local/mysql/bin.
Finalement, allez dans le dossier de données MySQL (il sera
probablement dans /var/lib/mysql ou
/usr/local/mysql/data). Assurez-vous que le
fichier my.cnf contient les options
nécessaires pour activer le moteur NDB
Cluster :
[mysqld] ndbcluster
Vous pouvez maintenant lancer le serveur MySQL comme d'habitude :
shell> mysqld_safe --user=mysql &
Attendez un moment, et assurez-vous que le serveur fonctionne
correctement. Si vous voyez un message ``mysql
ended'', vérifiez le fichier d'erreur du serveur
.err pour savoir ce qui se passe.
Si tout est bien allé, vous pouvez lancer le cluster :
shell>mysqlWelcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 to server version: 4.1.7-gamma Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>SHOW STORAGE ENGINES;+------------+---------+------------------------------------------------------------+ | Engine | Support | Comment | +------------+---------+------------------------------------------------------------+ ... | NDBCLUSTER | DEFAULT | Clustered, fault-tolerant, memory-based tables | | NDB | YES | Alias for NDBCLUSTER | ... mysql>USE test;Database changed mysql>CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER;Query OK, 0 rows affected (0.09 sec) mysql>show create table ctest \G*************************** 1. row *************************** Table: ctest Create Table: CREATE TABLE `ctest` ( `i` int(11) default NULL ) ENGINE=ndbcluster DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
Si vous voulez vérifier que vos noeuds ont été correctement configurés, vous pouvez lancer le client de gestion :
shell> ndb_mgm
Essayez d'utiliser la commande SHOW pour
avoir un aper¸u du cluster :
NDB> show Cluster Configuration --------------------- [ndbd(NDB)] 1 node(s) id=2 @127.0.0.1 (Version: 3.5.3, Nodegroup: 0, Master) [ndb_mgmd(MGM)] 1 node(s) id=1 @127.0.0.1 (Version: 3.5.3) [mysqld(API)] 3 node(s) id=3 @127.0.0.1 (Version: 3.5.3) id=4 (not connected, accepting connect from any host) id=5 (not connected, accepting connect from any host)
Le cluster est à vous!
- 16.4.4.1 Exemple de configuration d'un cluster MySQL
- 16.4.4.2 La chaîne
connectstringdu Cluster MySQL - 16.4.4.3 Définition des ordinateurs dans un cluster MySQL
- 16.4.4.4 Définition du serveur de gestion du cluster
- 16.4.4.5 Définitions des noeuds de stockage dans un cluster MySQL
- 16.4.4.6 Définition des serveurs MySQL dans un Cluster MySQL
- 16.4.4.7 Définition des connexions TCP/IP dans un cluster MySQL
- 16.4.4.8 Définition des connexions par mémoire partagée dans un cluster MySQL
- 16.4.4.9 Définition d'un transporteur SCI dans un cluster
La configuration d'un cluster MySQL est placée dans un fichier de configuration. Ce fichier est lu par le serveur de gestion, puis distribué à tous les processus qui sont impliqués dans le cluster. Ce fichier contient la description de toutes machines impliquées dans le cluster, les paramètres de configuration pour les noeuds de stockage et les paramètres de configuration entre les noeuds.
Actuellement, le fichier de configuration est au format INI,
et il s'appelle config.ini par défaut.
Il est placé dans le dossier de démarrage de
ndb_mgmd, le serveur de gestion.
Les options pré-configurées sont disponibles pour la plupart
des paramètres, et les valeurs par défaut peuvent être
définies dans le fichier config.ini.
Pour créer une section de valeurs par défaut, ajoutez le mot
DEFAULT au nom de la section. Par exemple,
les noeuds DB sont configurés avec la section
[DB]. Si tous les noeuds DB utilisent la
même quantité de mémoire, et que cette valeur n'est pas la
valeur par défaut, alors créez une section [DB
DEFAULT] qui contient le paramètre
DataMemory, et qui spécifiera la valeur
par défaut de la taille de mémoire des noeuds DB.
Le format INI est constitué de sections, précédées par des
entêtes de sections (entourées de crochets), suivi de
paramètres et leur valeur. Un changement par rapport au
format standard est que le paramètre et sa valeur peuvent
être séparés par un deux-points
‘:’ en plus du signe égal
‘=’, et un autre est que les
sections ne sont pas uniques. Au lieu de cela, les entrées
uniques comme deux noeuds du même type, sont identifiées par
un ID distinct.
Un fichier de configuration minimal doit définir les ordinateurs du cluster, et les noeuds impliquées, ainsi que les ordinateurs sur lesquels ces noeuds sont installés.
Un exemple de fichier de configuration minimal pour un cluster avec un serveur de gestion, deux serveurs de stockage et deux serveurs MySQL est présenté ci-dessous :
# file "config.ini" - 2 DB nodes and 2 mysqld # This file is placed in the start directory of ndb_mgmd, # the management server. # The first MySQL Server can be started from any host and the second # can only be started at the host mysqld_5.mysql.com # NDBD, MYSQLD, and NDB_MGMD are aliases for DB, API, and MGM respectively # [NDBD DEFAULT] NoOfReplicas= 2 DataDir= /var/lib/mysql-cluster [NDB_MGMD] Hostname= ndb_mgmd.mysql.com DataDir= /var/lib/mysql-cluster [NDBD] HostName= ndbd_2.mysql.com [NDBD] HostName= ndbd_3.mysql.com [MYSQLD] [MYSQLD] HostName= mysqld_5.mysql.com
Il y a ici 6 sections dans le fichier.
[COMPUTER] définit les ordinateurs du
cluster. [API|MYSQLD] définit les noeuds
de serveur MySQL du cluster. [MGM|NDB_MGMD]
définit le serveur de gestion du cluster.
[TCP] définit les connexions TCP/IP entre
les noeuds du cluster, TCP/IP est le mécanisme de connexion
par défaut entre deux noeuds. [SHM]
définit les connexions par mémoire partagée entre les
noeuds. Ce n'est possible que si les noeuds ont été compilé
avec l'option --with-ndb-shm.
Pour chaque section, il est possible de définir un
comportement par défaut, DEFAULT. Les
paramètres sont insensibles à la casse depuis MySQL 4.1.5.
A l'exception du serveur de gestion du cluster MySQL
(ndb_mgmd), chaque noeud du cluster MySQL a
besoin d'une chaine
connectstring qui pointe sur
le serveur de gestion. Elle sert à établir la connexion avec
le serveur de gestion, ainsi qu'à réaliser d'autres tâches
en fonction du rôle du noeud dans le cluster. La syntaxe pour
la chaîne connectstring est la suivante :
<connectstring> := [<nodeid-specification>,]<host-specification>[,<host-specification>] <nodeid-specification> := nodeid=<id> <host-specification> := <host>[:<port>]
<id> est un entier plus grand que 1
qui identifie un noeud dans le fichier
config.ini.
<port> est un entier qui représente
le port Unix. <host> est une chaîne
qui est une adresse valide d'hôte Internet.
example 1 (long): "nodeid=2,myhost1:1100,myhost2:1100,192.168.0.3:1200" example 2 (short): "myhost1"
Tous les noeuds vont utiliser
localhost:1186 comme chaîne par défaut,
si elle n'est pas spécifié. Si
<port> est omis dans la chaîne, le
port par défaut est 1186.
(Note : avant MySQL 4.1.8,
le port par défaut était 2200). Ce port doit toujours être
disponible sur le réseau, car il a été assigné par l'IANA
pour cela (voyez
http://www.iana.org/assignments/port-numbers
pour les détails).
En listant plusieurs valeurs
<host-specification>, il est possible
de désigner plusieurs serveurs de gestion redondants. Un
noeud de cluster va tenter de contacter successivement chaque
serveur, dans l'ordre spécifié, jusqu'à ce qu'une connexion
soit établie.
Il y existe plusieurs moyens de spécifier la chaîne
connectstring :
Chaque programme a sa propre option de ligne de commande qui permet de spécifier le serveur de gestion au démarrage. Voyez la documentation respective de chaque programme.
Depuis MySQL 4.1.8, il est aussi possible de configurer
connectstringpour chaque noeud du cluster en pla¸ant une section[mysql_cluster]dans le fichier de configuration du serveur de gestionmy.cnf.Pour la compatibilité ascendante, deux autres options sont disponibles en utilisant la même syntaxe :
Configurer la variable d'environnement
NDB_CONNECTSTRINGpour qu'elle contienneconnectstring.Placez la chaîne
connectstringpour chaque programme dans un fichier texte appeléNdb.cfget placez de fichier dans le dossier de démarrage.
La méthode recommandée pour spécifier la chaîne
connectstring est de passer par la ligne de
commande ou par le fichier my.cnf.
La section [COMPUTER] n'a pas d'autres
signification que de système de noms pour les noeuds du
système. Tous les paramètres cités ici sont obligatoires.
[COMPUTER]IdC'est l'identité interne dans le fichier de configuration. Ultérieurement, on appelera cette identifié un identifiant. C'est un entier.
[COMPUTER]HostNameCeci est le nom d'hôte de l'ordinateur. Il est possible d'utiliser une adresse IP plutôt que son nom d'hôte.
La section [MGM] (et son alias
[NDB_MGMD]) sert à configurer le
comportement du serveur de gestion. Le paramètre obligatoire
est soit ExecuteOnComputer, soit
HostName. Tous les autres paramètres
peuvent être omis, et ils prendront leur valeur par défaut.
[MGM]IdC'est l'identité du noeud, utilisée comme adresse dans les messages internes. C'est un entier compris entre 1 et 63. Chaque noeud du cluster a une identitée unique.
[MGM]ExecuteOnComputerFait référence à un des ordinateurs définit dans la section COMPUTEUR.
[MGM]PortNumberC'est le numéro de port que le serveur de gestion utilisera pour attendre les demandes de configuration et les commandes de gestion.
[MGM]LogDestinationCe paramètre spécifie la destination du log du cluster. Il y a plusieurs destinations possibles, et elles peuvent être utilisées en paralelle. Les valeurs possibles sont
CONSOLE,SYSLOGetFILE. Pour les configurer, il faut les mettre sur une même ligne, séparés par des points-virgules ';'.CONSOLEenvoie sur la sortie standard, et aucun autre paramètre n'est nécessaire.CONSOLE
SYSLOGcorrespond à l'envoi log système. Il est nécessaire d'indiquer une méthode ici. Les méthodes possibles sont :auth,authpriv,cron,daemon,ftp,kern,lpr,mail,news,syslog,user,uucp,local0,local1,local2,local3,local4,local5,local6,local7. Notez que toutes ces options ne sont pas forcément supportées par tous les systèmes d'exploitation.SYSLOG:facility=syslog
FILEreprésente un fichier standard sur la machine. Il est nécesaire de spécifier un nom de fichier, la taille maximale du fichier avant l'ouverture d'un nouveau fichier. L'ancien sera alors renommé avec l'extension.xoùxest le prochain nombre libre. Il est aussi nécessaire de spécifier le nombre maximal de fichiers utilisés.FILE:filename=cluster.log,maxsize=1000000,maxfiles=6
Il est possible de spécifier plusieurs destinations de logs comme ceci :
CONSOLE;SYSLOG:facility=local0;FILE:filename=/var/log/mgmd
La valeur par défaut de ce paramètre est
FILE:filename=cluster.log,maxsize=1000000,maxfiles=6.[MGM]ArbitrationRankCe paramètre est utilisé pour définir les noeuds qui servent d'arbitre. Les noeuds de gestion MGM et les noeuds API peuvent être utilisés comme arbitre. 0 signifie que le noeud n'est pas utilisé comme arbitre, 1 est la priorité haute, et 2 la priorité basse. Une configuration normale utilisent les serveurs de gestion comme arbitre avec ArbitrationRank à 1 (c'est la valeur par défaut) et les noeuds d'API à 0 (ce n'est pas le défaut en MySQL 4.1.3).
[MGM]ArbitrationDelaySi vous donnez une valeur différente de 0 à cette option, cela signifie que le serveur de gestion retarde ses réponses d'autant, lorsqu'il re¸oit des demandes d'arbitrage. Par défaut, il n'y a pas de délai, et c'est très bien comme ca.
[MGM]DataDirC'est le dossier où les fichiers de résultats du serveur de gestion seront placés. Ces fichiers sont les fichiers de log, les affichages de processus et le PID pour le démon.
La section [DB] (et son alias
[NDBD]) servent à configurer le
comportement des noeuds de stockage. Il y a de nombreux
paramètres spécifiés qui contrôlent les tailles de buffer,
les tailles de files ou les délais d'expiration, etc. Le seul
paramètre obligatoire est soit
ExecuteOnComputer ou
HostName et le paramètre
NoOfReplicas qui doit être défini dans la
section [DB DEFAULT]. La plupart des
paramètres doivent être dans la section [DB
DEFAULT]. Seuls les paramètres explicitement
présentés comme ayant une valeur local peuvent être
modifiés dans la section [DB].
HostName, Id et
ExecuteOnComputer doivent être définies
dans la section [DB].
La valeur de Id, ou l'identité d'un noeud
de stockage peut être allouée au démarrage du noeud. Il est
toujours possible d'assigner un identifiant dans un fichier de
configuration.
Pour chaque paramètre, il est possible d'utiliser les suffixes k, M ou G, pour indiquer des multiples 1024, (1024*1024) et (1024* 1024*1024) de l'unité. Par exemple, 100k représente 102400. Les paramètres et leur valeur sont actuellement sensibles à la casse.
[DB]IdCette identitiant est l'identité du noeud, utilisé pour référencer le noeud dans le cluster. C'est un entier compris entre 1 et 63. Chaque noeud du cluster doit avoir une identité distincte.
[DB]ExecuteOnComputerCela fait référence à un des ordinateurs définis dans la section 'Computer'.
[DB]HostNameCe paramètre revient à spécifier un ordinateur sur lequel placer l'exécution. Il définit un nom d'hôte sur lequel réside le noeud de stockage. Ce paramètre ou
ExecuteOnComputerest obligatoire.[DB]ServerPortChaque noeud dans le cluster utiliser un port pour se connecter avec les autres noeuds du cluster. Ce port est aussi utilisé pour les connexions lors de la phase de mise en place. Ce port par défaut sera utilisé pour s'assurer qu'aucun noeud sur le même ordinateur ne re¸oit le même numéro de port. Le numéro de port minimum est 2202.
[DB]NoOfReplicasCe paramètre ne peut être configuré que dans la section
[DB DEFAULT]car c'est un paramètre global. Il définit le nombre de répliques de chaque table stockée dans le cluster. Ce paramètre spécifie aussi la taille du groupe de noeuds. Un groupe de noeud est un ensemble de noeuds qui stockent les mêmes informations.Les groupes de noeuds sont formés implicitement. Le premier groupe est formé par les noeuds de stockage avec les identités les plus petites, puis par ordre d'identité croissante. Par exemple, supposons que nous avons 4 noeuds de stockage et que
NoOfReplicasvaut 2. Les quatres noeuds de stockage ont les identifiants 2, 3, 4 et 5. Le premier groupe de noeud sera formé par les noeuds 2 et 3, et le second groupe sera formé de 4 et 5. Il est important de configurer le cluster pour que les noeuds d'un même groupe ne soit pas placé sur le même ordinateur. Sinon, cela pourrait conduire à avoir un point de faiblesse : un seul ordinateur peut planter le cluster.Si aucune identité n'est spécifiée, alors l'ordre des noeuds de stockage va être le facteur déterminant du groupe de noeuds. Le groupe de noeud ainsi généré peut être affiché avec la commande
SHOWdans le client de gestion.Il n'y a pas de valeur par défaut, et la valeur maximale est 4.
[DB]DataDirCe paramètre spécifie le dossier où les fichiers de traces, les fichiers de log, et les fichiers d'erreurs sont rangés.
[DB]FileSystemPathCe paramètre spécifie le dossier où tous les fichiers créés pour stocker les meta-données, les logs de REDO, les logs de UNDO et les fichiers de données sont rangés. La valeur par défaut est
DataDir. Le dossier doit être créé avant de lancer le processus ndbd.Si vous utilisez la hierarchie de dossiers recommandée, vous utiliserez le dossier
/var/lib/mysql-cluster. Sous ce dossier, un autre dossierndb_2_fssera créé (si l'identifiant de noeud est 2), pour servir de fichier système pour le noeud.[DB]BackupDataDirIl est possible de spécifier le dossier où les sauvegardes seront placées. Par défaut, le dossier
FileSystemPath/BACKUPsera utilisé.
DataMemory et
IndexMemory sont les paramètrs qui
spécifient le taille des segments de mémoire utilisés pour
stocker les lignes et leur index. Il est important de
comprendre comment DataMemory et
IndexMemory sont utilisés pour comprendre
comment choisir ces paramètres. Pour la majorité des cas,
ils doivent être mis à jour pour refléter leur utilisation
dans le cluster.
[DB]DataMemoryCe paramètre est l'un des paramètres les plus importants, car il définit l'espace disponible pour stocker les lignes dans la bases de données. Tout l'espace
DataMemorysera alloué en mémoire : il est donc important que la machine contienne assez de mémoire pour stockerDataMemory.DataMemorysert à stocker deux choses. Il stocke les lignes de données. Chaque ligne est de taille fixe. Les colonnesVARCHARsont stockées sous forme de colonnes à taille fixe. De plus, chaque enregistrement est stocké dans une page de 32 ko avec 128 octets d'entête. Il y a donc un peu de pertes pour chaque page, car chaque ligne n'est stockée que sur une seule page. La taille maximale d'une colonne est actuellement de 8052 octets.DataMemorysert aussi à stocker les index ordonnés. Les index ordonnées prennent environs 10 octets par ligne. Chaque ligne dans une table est représentée par un index ordonné.DataMemoryest constitués de pages de 32ko. Ces pages sont allouées comme partitions pour les tables. Chaque table est généralement répartie en autant de partition qu'il y a de noeud dans le cluster. Par conséquent, il y a le même nombre de partition (fragments) que la valeur deNoOfReplicas. Une fois qu'une page a été allouée, n'est pas possible actuellement de la libérer. La méthode pour récupérer cet espace est d'effacer la table. Effecter une restauration de noeud va aussi compresser la partition, car toutes les lignes seront insérées dans une partition vide, depuis un autre noeud.Un autre aspect important est que
DataMemorycontient aussi les informations de UNDO (annulation) pour chaque ligne. Pour chaque modification d'une ligne, une copie de la ligne est faite dans l'espaceDataMemory. De plus, chaque copie va aussi avoir une instance dans l'index ordonné. Les index Hash unique sont modifié uniquement lorsque les colonnes uniques sont modifiées dans dans ce cas, une nouvelle entrée est insérée dans la table. Au moment de l'archivage (commit), l'ancienne valeur est effacée. Il est donc nécessaire de pouvoir allouer la mémoire nécessaire pour gérer les plus grosses transactions effectuée dans le cluster.Effectuer une transaction de grande taille n'a pas d'autre intérêt avec le Cluster MySQL que la cohérence, ce qui est la base des transactions. Les transactions ne sont pas plus rapides, et consomment beaucoup de mémoire.
La taille par défaut de
DataMemoryest 80MB. La taille minimum est de 1MB. Il n'y a pas de taille maximum, mais en réalité, il faut adapter la valeur pour éviter que le système n'utilise la mémoire sur le disque, par ce que la mémoire physique a été dépassée.[DB]IndexMemoryIndexMemoryest le paramètre qui contrôle la quantité d'espace utilisée pour les index hash de MySQL Cluster. Les index hash sont toujours utilisé pour les clés primaires, les index uniques et les contraintes d'unicité. En fait, lors de la définition d'une clé primaire et d'une clé unique, deux index distincts seront créés par MySQL CLuster. Un index sera un hash utilisé pour les accès aux lignes, et pour le verrouillage. Il est aussi utilisé pour les contraintes d'unicité.La taille d'un index hash est de 25 octets plus la taille de la clé primaire. Pour les clés primaires dont la taille dépasse 32 octets, ajoutez un autre 8 octets pour des références internes.
Par exemple, observons la table suivante.
CREATE TABLE example ( a INT NOT NULL, b INT NOT NULL, c INT NOT NULL, PRIMARY KEY(a), UNIQUE(b) ) ENGINE=NDBCLUSTER;Nous avons ici 12 octets d'entête (puisque des colonnes non nulles économisent 4 octets), plus 12 octets par ligne. De plus, nous avons deux index ordonnés sur les colonnes a et b, qui utilisent chacun 10 octets par ligne. Nous aurons aussi une clé primaire hash avec environ 29 octets par ligne. La contrainte unique est implémentée par une table séparée, avec b comme clé primaire et a comme colonne. Cette table va donc consommer encore 29 autres octets en mémoire par ligne, plus 12 octets d'entete et 8 octets pour les données.
Pour une table d'un million de lignes, nous aurons besoin de 58 Mo de mémoire pour gérer les index en mémoire, la clé primaire et la contrainte d'unicité. Pour
DataMemory, nous aurons besoin de 64Mo de mémoire, pour gérer les lignes de la table de base et celles de la table d'index, plus les deux tables d'index ordonnés.En conclusion, les index hash consomment beaucoup d'espace en mémoire vive, mais fournissent un accès accéléré aux données. Ils sont aussi utilisé dans les cluster MySQL pour gérer les contraintes d'unicité.
Actuellement, les seuls algorithmes de partitionnement sont le hashage et les index ordonnés, qui sont locaux à chaque noeud, et ne peuvent pas prendre en compte les contraintes d'unicité en général.
Un point important pour les deux options
IndexMemoryetDataMemoryest que le total de la base de données est la taille deDataMemoryetIndexMemorydans chaque groupe. Chaque groupe est utilisé pour stocker les informations répliquées, ce qui fait que si vous avez 4 noeuds avec 2 répliques, cela fait 2 groupes de noeuds, et le total deDataMemorydisponible est 2*DataMemorydans chaque noeud.Un autre aspect important est les modifications de
DataMemoryetIndexMemory. Tout d'abord, il est fortement recommandé d'avoir la même quantité deDataMemoryetIndexMemorysur tous les noeuds. Comme les données sont distribuées équitablement entre les noeuds du cluster, l'espace disponible n'est pas supérieure à la plus petite quantité d'espace disponible sur un des noeuds du cluster, multiplié par le nombre de groupe de noeuds.DataMemoryetIndexMemorypeuvent être modifiés, mais il est dangeureux de le réduire, car cela peut conduire à des problèmes de redémarrage pour un noeud, ou même pour le cluster, car il n'y aura plus assez de mémoire pour restaurer les tables. Accroitre les valeurs doit être facile à faire, mais il est recommandé, pour ce type de mise à jour, de faire une modification comparable à une mise à jour du logiciel : modification du fichier du fichier de configuration, puis redémarrage du serveur de gestion, et chaque serveur est relancé manuellement, un à la fois.IndexMemoryn'est pas utilisé à cause des modifications mais à cause des insertions : ces dernières sont insérées immédiatement, alors que les effacements ne sont pris en compte que lorsque la transaction est archivée.La valeur par défaut de
IndexMemoryest 18Mo. La taille minimale est de 1Mo.
Les trois paramètres suivants sont importants car ils
affectent le nombre de transactions simultanées et la taille
des transactions qui peuvent être gérée par le système.
MaxNoOfConcurrentTransactions fixe le
nombre de transactions simultanées dans un noeud, et
MaxNoOfConcurrentOperations fixe le nombre
de ligne qui peuvent être en phase de modification ou de
verrouillage simultanément.
Ces deux paramètres, et particulièrement
MaxNoOfConcurrentOperations seront
étudiées de près par les utilisateurs qui choisissent des
valeurs particulières, et évitent les valeurs par défaut.
La valeur par défaut est configurée pour les systèmes ayant
de petites transaction, et s'assure que la mémoire n'es pas
trop sollicitée.
[DB]MaxNoOfConcurrentTransactionsPour chaque transaction active dans le cluster, il y a besoin d'une ligne de transaction dans l'un des noeuds du cluster. Le rôle de cette coordination de transaction est réparti entre tous les noeuds et ainsi, le nombre de lignes de transactions dans le cluster est le nombre de noeuds dans le cluster.
En fait, les lignes de transactions sont allouées aux serveurs MySQL. Normalement, il y a au moins une ligne de transaction allouée dans le cluster par connexion qui utilise ou a utilisé une table dans le cluster. Par conséquent, il faut s'assurer qu'il y a plus de lignes de transaction dans le cluster qu'il n'y a de connexions simultanées à tous les serveurs du cluster MySQL.
Ce paramètre doit être le même pour tous les noeuds du serveur.
Modifier ce paramètre n'est jamais facile, et peut conduire à un crash du système. Lorsqu'un noeud crashe, le noeud le plus ancien va prendre en charge l'état des transactions qui avaient lieu dans le noeud perdu. Il est donc important que ce noeud ait autant de lignes de transactions que le noeud perdu.
La valeur par défaut pour ce paramètre est 4096.
[DB]MaxNoOfConcurrentOperationsCe paramètre est sujet à modifications par les utilisateurs. Les utilisateurs qui effectuent des transactions courtes et rapides n'ont pas besoin de lui donner une valeur trop haute. Les applications qui veulent utiliser des transactions de grande taille, impliquant de nombreuses lignes devront accroître sa valeur.
Pour chaque transaction qui modifie des données dans le cluster, il faut allouer des lignes d'opération. Il y a des lignes d'opération au niveau de la coordination de transaction, et dans les noeuds où les transformations ont lieu.
Les lignes d'opération contiennent des informations d'état qui doivent être capables de retrouver des lignes d'annulation, des files de verrous et toutes les autres informations d'état.
Pour dimensionner le cluster afin de gérer des transactions où un million de lignes doivent être mises à jours simultanément, il faut donner à ce paramètre la valeur d'un million divisé par le nombre de noeuds. Pour un cluster ayant 4 noeuds de stockage, la valeur sera donc de 250000.
De plus, les lectures qui posent des verrous utilisent aussi des lignes d'opération. De la mémoire supplémentaire est allouée dans les noeuds locaux pour gérer les cas où la distribution n'est pas parfaite entre les noeuds.
Lorsqu'une requête impose l'utilisation d'un index hash unique, il y aura automatiquement 2 lignes d'opération pour chaque ligne de la transaction. La première représente la lecture dans la table d'index, et la seconde gère l'opération dans la table de base.
La valeur par défaut pour ce paramètre est 32768.
Ce paramètre gère en fait 2 aspects qui peuvent être configurés séparément. Le premier aspect spécifie le nombre de lignes d'opérations qui peuvent être placés dans la coordination de transaction. Le second aspect spécifie le nombre de lignes d'opérations qui seront utilisées dans la base de données locale.
Si une très grande transaction est effectuée sur un cluster de 8 noeuds, elle aura besoin d'autant de lignes d'opération pour la coordination de transaction qu'il y a de lecture, modification et effacement impliquées dans la transaction. La transaction va répartir les lignes d'opération entre les 8 noeuds. Par conséquent, s'il est nécessaire de configuer le système pour une grosse transaction, il est recommandé de configurer les noeuds séparément.
MaxNoOfConcurrentOperationsva toujours être utilisé pour calculer le nombre de lignes d'opérations dans la coordination de transaction.Il est aussi important d'avoir une idée des contraintes de mémoire pour ces lignes d'opération. En MySQL 4.1.5, les lignes d'opération consomment 1Ko par ligne. Ce chiffre est appelé à réduire dans les versions 5.x.
[DB]MaxNoOfLocalOperationsPar défaut, ce paramètre est calculé comme 1,1 fois
MaxNoOfConcurrentOperationsce qui est bon pour les systèmes avec de nombreuses requêtes simultanées, de petite taille. Si la configuration doit gérer une très grande transaction une fois de temps en temps, et qu'il y a de beaucoup de noeuds, il est alors recommandé de configurer cette valeur séparément.
Le jeu de paramètres suivants sont utilisés pour le stockage temporaire durant l'exécution d'une requête dans le cluster. Toute cette mémoire sera libérée lorsque la requête sera terminée, et que la transaction attendra l'archivage ou l'annulation.
La plupart des valeurs par défaut de ces paramètres sera valables pour la plupart des utilisateurs. Certains utilisateurs exigeants pourront augmenter ces valeurs pour améliorer le paralellisme du système, et les utilisateurs plus contraintes pourront réduire les valeurs pour économiser de la mémoire.
[DB]MaxNoOfConcurrentIndexOperationsPour les requêtes utilisant un index unique hash, un autre jeu de lignes d'opération sont temporairement utilisées durant la phase d'exécution de la requête. Ce paramètre configure la taille de la file qui acceuille ces lignes. Par conséquent, cette mémoire n'est utilisée que lors de l'exécution d'une requête, et dès la fin de l'exécution, les lignes sont libérées. L'état nécessaire pour gérer les annulations et archivages est géré par les lignes d'opérations permanantes, où la taille de la file est gérée par
MaxNoOfConcurrentOperations.La valeur par défaut pour ce paramètre est 8192. Seuls les situations où un très haut niveau de paralellisme utilisant des index uniques hash doivent augmenter cette valeur. La réduction de cette valeur permet d'économiser de la mémoire, si l'administrateur est certains que le paralellisme reste rare dans le cluster.
[DB]MaxNoOfFiredTriggersLa valeur par défaut pour
MaxNoOfFiredTriggersest 4000. Normalement, cette valeur doit être suffisante pour la plupart des systèmes. Dans certains cas, il est possible de réduire cette valeur si le paralellismen n'est pas trop haut dans le cluster.Cette option est utilisée lorsqu'une opération est effectuée, et affecte un index hash unique. Modifier une colonne qui fait partie d'un index unique hash ou insérer/effacer une ligne dans une table avec un index unique hash va déclencher une insertion ou un effacement dans l'index de la table. Cette ligne est utilisée durant l'attente de la fin de l'exécution de cette opération. C'est une ligne qui ne dure pas longtemps, mais elle peut malgré tout réclamer plusieurs lignes pour des situations temporaires d'écritures paralelles sur la table de base, contenant les index uniques.
[DB]TransactionBufferMemoryCe paramètre est aussi utilisé pour lister les opérations de modifications d'index. Elle garde les informations de clé et colonne de l'opération en cours. Il doit être exceptionnel de modifier ce paramètre.
De plus, les opérations de lecture et écriture utilisent un buffer similaire. Ce buffer est encore plus temporaire dans son utilisation, ce qui fait que c'est un paramètre de compilation, qui vaut 4000*128 octets (500Ko). Le paramètre st
ZATTRBUF_FILESIZEdansDbtc.hpp. Un buffer similaire pour les informations de clé, qui représente 4000*16 octets, soit 62.5ko d'espace. Ce paramètre estZDATABUF_FILESIZEdansDbtc.hpp.Dbtcest le module qui gère la coordination de transaction.Des paramètres similaires existents dans le module
Dblqhpour gérer les lectures et modifications lorsque les données ont été localisées. DansDblqh.hppavecZATTRINBUF_FILESIZEqui vaut 10000*128 octets (1250ko) etZDATABUF_FILE_SIZE, qui vaut 10000*16 octets (environ 156ko). Nous n'avons aucune connaissance de situation qui soient limitées par ces valeurs.La valeur par défaut de
TransactionBufferMemoryest 1Mo.[DB]MaxNoOfConcurrentScansCe paramètre est utilisé pour contrôler la quantité de scans paralelles qui sont effectués dans le cluster. Chaque coordination de transaction peut gérer un certain nombre de scan de tables simultanément, et ce nombre est limité par cette option. Chaque partition va utiliser une ligne de scan dans le noeud où la partition est située. Le nombre de lignes est la taille de ce paramètre multiplié par le nombre de noeuds, ce qui fait que le cluster peut supporter le nombre maximal de scan, multiplié par le nombre de noeuds du cluster.
Les scans sont effectués dans deux situations. La première est lorsqu'aucun index hash ou ordonné n'a pu être trouvé pour gérer la requête. Dans ce cas, la requête est exécutée avec un scan de table. La seconde est lorsqu'il n'y a pas d'index hash, mais seulement un index ordonné. Utiliser l'index ordonné, revient à faire un scan de table paralelle. Comme l'ordre n'est conservé que dans les partitions locales, il est nécessaire de faire le scan dans toutes les partitions.
La valeur par défaut de
MaxNoOfConcurrentScansest 256. La valeur maximale est de 500.Ce paramètre va toujours spécifier le nombre de scans possibles dans la coordination de transaction. Si le nombre local de scan n'est pas fournit, il est calculé comme le produit de
MaxNoOfConcurrentScanset du nombre de noeuds de stockages du système.[DB]MaxNoOfLocalScansIl est possible de spécifier le nombre de lignes de scan locaux, si les scans ne sont pas totalement paralelles.
[DB]BatchSizePerLocalScanCe paramètre est utilisé pour calculer le nombre de lignes de verrous qui est nécessaire pour gérer les opérations de scans courantes.
La valeur par défaut est 64 et cette valeur est très liée au paramètre
ScanBatchSizedéfini dans l'interface des noeuds.[DB]LongMessageBufferCeci est un buffer interne utilisé pour passer des messages au noeuds, et entre les noeuds. Il est hautement improbable que quiconque veuille modifier cette valeur, mais il est malgré tout disponible. Par défaut, ce paramètre vaut 1Mo.
[DB]NoOfFragmentLogFilesCeci est un paramètre important qui indique la taille du fichier de log de REDO. Les logs REDO sont organisés en boucle, et il est important que la fin et le début ne se chevauchent pas. Lorsque la queue et la tête se rapprochent dangeureusement l'un de l'autre, le noeud va commencer à annuler les modifications, car il n'y a plus de place pour les lignes de modifications.
Le log de REDO n'est pas supprimés jusqu'à ce que trois jalons locaux soient passés depuis l'insertion dans le log. La vitesse d'apparition d'un jalon est contrôlée par un jeu de paramètres : tous ces paramètres sont donc liés.
La valeur par défaut de ce paramètre est 8, ce qui signifie que 8 jeux de 4*16Mo fichiers. Cela représente un total de 512Mo. L'unité de stockage est de 64Mo pour le log de REDO. Dans les serveurs a fort taux de modification, il faut augmenter considérablement cette valeur. Nous avons vu des cas de test où il a fallu mettre cette valeur à plus de 300.
Si les jalons sont lents à venir, et qu'il y a tellement d'écritre dans la base que les fichiers de logs sont remplis, que le fichier de log de queue ne peut pas être supprimé pour assurer la restauration, les transactions de modification seront interrompues avec une erreur interne 410, qui sera transformée en message :
Out of log file space temporarily. Cette condition restera en place jusqu'à ce qu'un jalon soit atteint, et que la queue du log puisse avancer.[DB]MaxNoOfSavedMessagesCe paramètre limite le nombre de fichiers de trace qui seront conservés sur le serveur, avant de remplacer un ancien fichier de trace. Les fichiers de trace sont générés lorsque le noeud crash pour une raison donnée.
La valeur par défaut est de 25 fichiers de trace.
Le jeu de paramètres suivant défini la taille du buffer de d'objets de meta-données. Il est nécessaire de définir le nombre maximal d'objets, d'attributs, d'index et d'objets triggers utilisés par les index, les événements, et la réplication entre clusters.
[DB]MaxNoOfAttributesCe paramètre définit le nombre d'attributs qui peuvent être définis dans le cluster.
La valeur par défaut pour ce paramètre est 1000. La valeur minimale est 32 et il n'y a pas de maximum. Chaque attribut consomme environ 200 octets d'espace, car les meta-données sont totalement répliqués entre les noeuds.
[DB]MaxNoOfTablesUn objet de table est alloué pour chaque table, pour chaque index hash unique et pour chaque index ordonné. Ce paramètre fixe le nombre maximal d'objet de table qui soit alloué.
Pour chaque attribut qui contient un type de données
BLOB, une autre table est utilisée pour stocker la partie principale des donnéesBLOB. Ces tables doivent aussi êtr prises en compte lorsque vous définissez les tables.La valeur par défaut pour ce paramètre est 128. La valeur minimale est de 8, et il n'y a pas de maximum. Il y a des limitations internes, qui empêchent d'aller au dela de 1600. Chaque objet de table consomme environs 20ko de mémoire par noeud.
[DB]MaxNoOfOrderedIndexesPour chaque index ordonnée dans le cluster, des objets sont alloués pour décrire ce qu'ils indexent et leurs stockage. Par défaut, chaque index défini aura un index ordonné associé. Les index uniques et les clés primaires ont tous deux un index ordonné et un index hash.
La valeur par défaut pour ce paramètre est 128. Chaque objet consomme environ 10ko par noeud.
[DB]MaxNoOfUniqueHashIndexesPour chaque index unique (pas pour les index primaires), un table spéciale est allouée pour assurer la correspondance entre la clé primaire et la clé unique de la table indexée. Par défaut, il y aura un index ordonné de défini pour chaque index unique. Pour éviter cela, utilisez l'option
USING HASH.La valeur par défaut de 64. Chaque index va consommer environ 15ko par noeud.
[DB]MaxNoOfTriggersPour chaque index hash unique, un trigger interne de modification, insertion ou effacement est alloué. Cela fait 3 triggers pour chaque index hash unique. Les index ordonnées utilisent un seul objet trigger. Les sauvegardes utilisent aussi trois objets trigger pour chaque table normale dans le cluster. Lorsque la réplication entre cluster est supportée, elle va aussi utiliser un trigger interne.
Ce paramètre limite le nombre d'objet trigger dans le cluster.
La valeur par défaut pour ce paramètre est 768.
[DB]MaxNoOfIndexesCe paramètre est abandonnée depuis MySQL 4.1.5. Il faut désormais utiliser
MaxNoOfOrderedIndexesetMaxNoOfUniqueHashIndexesà la place.Ce parmètre ne sert que pour les index hash unique. Il faut une ligne dans ce buffer pour chaque index hash unique défini dans le cluster.
La valeur par défaut pour ce paramètre est 128.
Il y a un jeu de paramètre booléens qui affectent le comportement des noeuds de stockage. Les paramètres booléens peuvent être spécifiés à true avec Y (pour Yes, c'est-à-dire oui) ou 1, et à false avec N (pour non) ou 0.
[DB]LockPagesInMainMemoryPour certains systèmes d'explications tels que Solaris et Linux, il est possible de verrouiller un processus en mémoire et éviter les problèmes de swap. C'est une fonctionnalité important pour améliorer le temps réel du cluster.
Par défaut, cette fonctionnalité n'est pas activée.
[DB]StopOnErrorCe paramètre indique si le processus doit s'arrêter sur une erreur, ou s'il doit faire un redémarrage automatique.
Par défaut, cette fonctionnalité est activée.
[DB]DisklessDans les interfaces internes, il est possible de configurer les tables comme sans disque (littéralement,
diskless), ce qui signifie que les tables ne sont pas enregistrées sur le disque, et qu'aucun log n'est fait. Ces tables existent uniquement en mémoire. Ces tables existeront encore après un crash, mais pas leur contenu.Cette fonctionnalité fait que le cluster entier devient
Diskless, ce qui fait le les tables n'existent plus après un crash. Activer cette fonctionnalité de fait avec Y ou 1.Lorsque cette fonctionnalité est activée, les sauvegardes sont faites, mais elles ne seront pas stockées car il n'y a pas de disque. Dans les versions futures, il est probable que les sauvegardes sans disques soient une option séparée.
Par défaut, cette fonctionnalité n'est pas activée.
[DB]RestartOnErrorInsertCette fonctionnalité n'est possible que lorsque la version de déboguage a été compilée, pour pouvoir insérer des erreurs à différents points de l'exécution, afin de tester les cas d'erreurs.
Par défaut, cette fonctionnalité n'est pas activée.
Il y a plusieurs paramètres pour tester les délais d'expirations et les interfavalles entre différentes actions des noeuds de stockage. Plusieurs délais d'expiration sont spécifiés en millisecondes, à quelques exceptions qui sont explicitement indiquées.
[DB]TimeBetweenWatchDogCheckPour s'assurer que le thread principal ne reste back éternellement bloqué dans une boucle infinie, il existe un garde-fou qui vérifie le fonctionnement de ce thread. Ce paramètre indique le nombre de millisecondes entre deux vérifications. Après trois essais où le processus est dans le même état, le thread est arrêté par le garde-fou.
Ce paramètre peut être facilement modifié, et peut différer de noeud en noeud, même s'il y a peu de raison pour faire des traitements différents.
La durée par défaut est de 4000 millisecondes (4 secondes).
[DB]StartPartialTimeoutCe paramètre spécifie le temps durant lequel le cluster attend les noeuds de stockage avant que l'algorithme de cluster soit appelé. Cette durée est appelée pour éviter de démarrer un cluster partiel.
La valeur par défaut de 30000 millisecondes (30 secondes). 0 signifie l'éternité, c'est à dire que tous les noeuds doivent être là pour démarrer.
[DB]StartPartitionedTimeoutSi le cluster est prêt à démarrer après avoir attendu
StartPartialTimeoutmais qu'il est possible qu'il soit dans un état de partionnement, alors le cluster attend encore ce délai supplémentaire.Le délai par défaut est de 60000 millisecondes (60 secondes).
[DB]StartFailureTimeoutSi le démarrage n'est pas réalisé dans le délai spécifié par ce paramètre, le démarrage du noeud échouera. En donnant la valeur de 0 à ce paramètre, il n'y au pas de délai appliqué.
La valeur par défaut de 60000 millisecondes (60 secondes). Pour les noeuds de stockage avec de grandes bases de données, il faut augmenter cette valeur car le noeud peut demander jusqu'à 15 minutes pour effectuer le démarrage de plusieurs gigaoctets de données.
[DB]HeartbeatIntervalDbDbUne des méthodes qui permet de découvrir les noeuds morts est la tachycardie (littéralement,
heartbeats, battement de coeur). Ce paramètre indique le nombre de signaux qui sont envoyés, et la fréquence supposée de reception. Après avoir sauté 3 intervalles de signaux d'affilée, le noeud est déclaré mort. Par conséquent, le temps maximal de détection d'un noeud est de 4 battements.L'intervalle par défaut est de 1500 millisecondes (1.5 secondes). Ce paramètre ne doit pas être modifié de trop. Si vous utilisez 5000 millisecondes et que le noeud observé utiliser une valeur de 1000 millisecondes alors ce dernier sera rapidement déclaré mort. Ce paramètre peut être modifié progressivement, mais pas trop d'un coup.
[DB]HeartbeatIntervalDbApiSimilairement, chaque noeud de stockage émet des signaux de vie pour chaque serveur MySQL connecté, pour s'assurer qu'ils fonctionnent correctement. Si un serveur MySQL ne renvoie pas un signal dans le temps escompté, avec le même algorithme que pour la surveillance des noeuds de stockage, il est alors déclaré mort, et les transactions sont alors terminées, les ressources libérées, et le serveur ne pourra pas se reconnecter avant la fin des opérations de nettoyage.
La valeur par défaut pour cet intervalle est 1500 millisecondes. Cet interval peut être différent pour le noeud de stockage, car chaque noed de stockage fonctionne indépendamment des autres noeuds de stockage qui surveille le serveur connecté.
[DB]TimeBetweenLocalCheckpointsCe paramètre est une exception, en ce send qu'il ne définit pas un délai avant de poser un jalon local. Ce paramètre sert à s'assurer que dans un cluster, le niveau de modification des tables n'est pas trop faible pour empêcher la pose de jalon. Dans la plupart des clusters avec un taux de modification important, il est probable que les jalons locaux soient posés immédiatement après la fin du précédent.
La taille de toutes les opérations d'écriture exécutées depuis le début du jalon précédent est sommée. Ce paramètreset spécifié comme le logarithme du nombre de mots. Par exemple, la valeur par défaut de 20 signifie que 4Mo d'opérations d'écriture ont été faites; 21 représente 8Mo, et ainsi de suite. La valeur maximale de 31 représente 8Go d'opérations.
Toutes les opérations d'écritures dans le cluster sont additionnées ensemble. En lui donnant une valeur de 6 ou moins, cela va forcer les écritures de jalons continuellement, sans aucune attente entre deux jalons, et indépendemment de la charge du cluster.
[DB]TimeBetweenGlobalCheckpointsLorsqu'une transaction est archivée, elle est placée en mémoire principale de tous les noeuds où des données miroirs existent. Les lignes de logs de la transaction ne sont pas forcées sur le disque lors de l'archivage. L'idée ici est que pour que la transaction soit archivé sans problème, il faut qu'elle soit archivée dans 2 noeuds indépendants.
Dans le même temps, il est important de s'assurer que dans le pire cas de crash, le cluster se comporte correctement. Pour s'assurer que les transactions dans un intervalle de temps donné sont placées dans un jalon global. Un groupe entier de transaction est envoyé sur le disque. Par conséquent, la transaction a été placée dans un groupe de jalon, en tant que partie d'un archivage. Ultérieurement, ce groupe de log sera placé sur le disque , et le groupe entier de transaction sera archivé sur tous les serveurs.
Ce paramètre spécifie l'intervalle entre les jalons globaux. La valeur par défaut est de 2000 millisecondes.
[DB]TimeBetweenInactiveTransactionAbortCheckUn délai d'expiration est appliqué pour chaque transaction en fonction de ce paramètre. Par conséquent, si ce paramètre vaut 1000 millisecondes, alors chaque transaction sera vérifée une fois par seconde.
La valeur par défaut pour ce paramètre est 1000 millisecondes (1 seconde).
[DB]TransactionInactiveTimeoutSi la transaction n'est pas en exécution de requête, mais attend d'autres données, ce paramètre spécifie le temps maximum d'attente des données avant d'annuler la transaction.
Par défaut, ce paramètre ne limite pas l'arrivée des données. Pour des cluster en production, qui doivent s'assurer qu'aucune transaction ne bloque le serveur durant trop longtemp, il faut utiliser une valeur basse. L'unité est la millisecondes.
[DB]TransactionDeadlockDetectionTimeoutLorsqu'une transactioon est implique dans l'exécution d'une requête, elle attend les autres noeuds. Si les autres noeuds ne répondent pas, il peut se passer 3 choses. Premièrement, le noeud peut être mort; deuxièment, l'opération peut être placée dans une file d'attente de verrou; troisièmement, le noeud impliqué peut être surchargé. Ce paramètre limite la durée de l'attente avant d'annuler la transaction.
Ce paramètre est important pour la détection d'échec de noeud et le blocage de verrou. En le configurant trop haut, il est possible de laisser passer des blocages.
La durée par défaut est de 1200 millisecondes (1.2 secondes).
[DB]NoOfDiskPagesToDiskAfterRestartTUPLors de l'exécution d'un jalon local, l'algorithme envoie toutes les pages de données au disque. Les envoyer aussi rapidement que possible cause des charges inutiles sur le processeur, le réseau et le disque. Cette option contrôle le nombre de page à écrire par 100 millisecondes. Une page est définie ici comme faisant 8ko. C'est l'unité de ce paramètre est de 80ko par seconde. En lui donnant la valeur de 20, cela représente 1.6Mo de données envoyées sur le disque par seconde, durant un jalon local. De plus, l'écriture des log de UNDO est inclus dans cette somme. L'écriture des pages d'index (voir
IndexMemorypour comprendre comment les pages d'index sont utilisées), et leur logs d'UNDO sont gérées par le paramètreNoOfDiskPagesToDiskAfterRestartACC. Ce paramètre paramètre gère les limitations d'écriture deDataMemory.Ainsi, ce paramètre spécifie la vitesse d'écriture des jalons. Ce paramètre est important et est corrélé à
NoOfFragmentLogFiles,DataMemory,IndexMemory.La valeur par défaut de 40 (3.2Mo de pages de données par seconde).
[DB]NoOfDiskPagesToDiskAfterRestartACCCe paramètre a la même unité que
NoOfDiskPagesToDiskAfterRestartTUPmais limite la vitesse d'écriture des pages d'index depuisIndexMemory.La valeur par défaut pour ce paramètre est 20 (1.6Mo par seconde).
[DB]NoOfDiskPagesToDiskDuringRestartTUPCe paramètre spécifie les mêmes limitations que
NoOfDiskPagesToDiskAfterRestartTUPetNoOfDiskPagesToDiskAfterRestartACC, mais s'appliquent aux jalons locaux, exécutés sur un noeud comme une partie de jalon lors du redémarrage. Faisant partie du redémarrage, un jalon local est toujours effectué. Il est possible d'utiliser une vitesse accrue durant le redémarrage du noeud, car les activités sont alors limitées sur le serveur.Ce paramètre gère la partie de
DataMemory.La valeur par défaut de 40 (3.2Mo par seconde).
[DB]NoOfDiskPagesToDiskDuringRestartACCDurant le redémarrage de la partie local de
IndexMemorypour un jalon local.La valeur par défaut de 20 (1.6Mo par seconde).
[DB]ArbitrationTimeoutCe paramètre spécifie le temps que le noeud de stockage va attendre un message de l'arbitre lors d'un fractionnement du réseau.
La valeur par défaut de 1000 millisecondes (1 seconde).
De nombreux nouveaux paramètres de configuration ont été introduits en MySQL 4.1.5. Ils correspondent à des valeurs qui étaient auparavant configurées durant la compilation. La raison principale à cela est qu'elles permettent aux utilisateurs experts de contrôler la taille du processus et d'ajuster les différentes tailles de buffer, en fonction de ses besoins.
Tous ces buffers sont utilisés comme interface avec le
système de fichiers lors de l'écriture des lignes de log sur
le disque. Si le noeud fonctionne en mode sans disque, ces
paramètres peuvent prendre leur valeur minimale, car les
écriture sur le disques sont simulées et toujours validées
par la couche d'abstraction du moteur NDB.
[DB]UndoIndexBufferCe buffer est utilisé durant les jalons locaux. Le moteur de stockage
NDButilise un mécanisme de restauration basé sur des jalons cohérents avec le log de REDO. Afin de produit un jalon valide sans bloquer le système l'enregistrement des UNDO est fait durant l'éxécution des jalons locaux. Le log de UNDO n'est activé que pour un fragment de table à chaque fois. Cette optimisation est rendue possible car les tables sont entièrement stockées en mémoire principale.Ce buffer est utilisé pour les modification dans les index hash de clé primaire. Les insertions et les effacement réarrange les index hash, et le moteur
NDBécrit les log d'UNDO qui associent les modifications physiquesw avec un index de page pour qu'ils puissent être appliqués même après un redémarrage. Toutes les insertions actives sont aussi enregistrées au début d'un jalon local, pour chaqu fragment.Les lectures et modifications ne font que poser des bits de verrouillages, et altèrent un entête dans la ligne d'index. Ces modifications sont gérées par l'algorithme d'écriture des pages, pour s'assurer que ces opérations n'ont pas besoin du log d'UNDO.
Ce buffer vaut 2Mo par défaut. La valeur minimale est 1Mo. Pour la plupart des applications, c'est suffisant. Les applications qui font beaucoup d'insertions et d'effacement avec de grandes transactions en exploitant intensivement leurs clés primaires devront agrandir ce buffer.
Si le buffer est trop petit, le moteur
NDBémet une erreur de code 677 qui se traduit pas "Index UNDO buffers overloaded".[DB]UndoDataBufferCe buffer a exactement le même role que
UndoIndexBuffermais est utilisée pour les données. Ce buffer est utilisé durant l'exécution d'un jalon local pour un fragment de table, et les insertions, les effacements et les modifications utilisent ce buffer.Comme les lignes du log d'UNDO tendent à être plus grandes et que plus d'informations sont stockées, ce buffer doit être aussi de plus grande taille. Par défaut, il vaut 16Mo. Pour certaines applications, cela peut être sur-dimensionné, et il est alors recommandé de réduire cette valeur. La taille minimale est de 1Mo. Il sera rare d'avoir à augmenter cette valeir. Si cette valeur doit être augmentée, commencez par vérifier vos disques et leurs performances. Si ce sont les disques qui limitent le débit, le buffer sera alors bien dimensionné.
Si ce buffer est trop petit et se remplit, le moteur
NDBémet une erreur de code 891 qui se traduit par"Data UNDO buffers overloaded".[DB]RedoBufferToutes les activités de modification doivent être enregistrées. Cela permet de repasser ces opérations au redémarrage du système. L'algorithme de restauration utilise un jalon cohérent, produit par un jalon "flou" produit par les données couplées aux pages de log d'UNDO. Puis, le log de REDO est appliqué pour rejouer toutes les modifications qui ont eu lieu depuis le redémarrage du système.
Ce buffer fait 8Mo par défaut. Sa taille minimale est de 1Mo.
Si ce buffer est trop etit, le moteur
NDBémet une erreur de code 1221 qui se traduit par :"REDO log buffers overloaded".
Pour la gestion du cluster, il est important de pouvoir contrôler la quantité de message de log qui sont envoyé à stdout par les différents événements qui surviennent. Les événements seront bientôt listés dans ce manuel. Il y a 16 niveaux possibles, allant de 0 à 15. En utilisant un niveau de rapport d'erreur de 15, toutes les erreurs seront rapportées. Un niveau de rapport d'erreur nul (0) bloquera toutes les erreurs.
La raison qui fait que la plupart des valeurs par défaut sont à 0, et qu'elles ne causent aucun affichage sur est que le même message est envoyé au log du cluster sur le serveur de gestion. Seul le message de démarrage est envoyé à stdout.
Un jeu de niveau d'erreur similaire peut être configuré dans le client de gestion, pour définir les niveaux d'erreurs qui doivent rejoindre le log du cluster.
[DB]LogLevelStartupEvenements générés durant le démarrage du processus.
Le niveau par défaut est 1.
[DB]LogLevelShutdownEvenements générés durant l'extinction programmée d'un noeud.
Le niveau par défaut est 0.
[DB]LogLevelStatisticEvenements statistiques tels que le nombre de clés primaires lues, le nombre d'insertions, modifications et de nombreuses autres informations statistiques sur l'utilisation des buffer.
Le niveau par défaut est 0.
[DB]LogLevelCheckpointEvenements générés par les jalons locaux et globaux.
Le niveau par défaut est 0.
[DB]LogLevelNodeRestartEvenements générés par un redémarrage de noeud.
Le niveau par défaut est 0.
[DB]LogLevelConnectionEvenements générés par les connexions entre les noeuds dans le cluster.
Le niveau par défaut est 0.
[DB]LogLevelErrorEvenements générés par les erreurs et alertes dans le cluster. Ces erreurs ne sont pas causées par un échec de noeud, mais sont suffisamment importantes pour être rapportées.
Le niveau par défaut est 0.
[DB]LogLevelInfoEvenements générés pour informer sur l'état du cluster.
Le niveau par défaut est 0.
Il existe un jeux de paramètres qui définissent les buffers mémoire qui sont utilisés pour l'exécution des sauvegardes en ligne.
[DB]BackupDataBufferSizeLors de l'exécution d'un sauvegarde, il y a deux buffers utilisés pour envoyer des données au disque. Ce buffer sert à rassembler des données obtenues par le scan des tables du noeud. Lorsque le regroupement atteint un certain niveau, ces pages sont envoyées au disque. Ce niveau est spécifié par le paramètre
BackupWriteSize. Lors de l'envoi des données sur le disque, la sauvegarde continue de remplir ce buffer, jusqu'à ce qu'il n'y ait plus de place. Lorsque la place manque, la sauvegarde marque une pause, et attent que l'écriture ait libéré de la mémoire avant de poursuivre.La valeur par défaut de 2Mo.
[DB]BackupLogBufferSizeCe paramètre a un rôle similaire mais sert à écrire un log de toutes les écritures dans la table durant l'exécution de la sauvegarde. Le même principe s'applique à l'écriture de ces pages que pour
BackupDataBufferSize, hormis le fait que lorsque la place manque, la sauvegarde échoue par manque de place. Par conséquent, la taille de ce buffer doit être assez grande pour encaisser la charge causée par les activités d'écriture durant l'exécution de la sauvegarde.La valeur par défaut de ce paramètre doit être assez grande. En fait, il est plus probable qu'une erreur de sauvegarde soit causée par le disque qui ne peut suivre la vitesse d'écriture. Si le disque est sous-dimensionné pour cette opération, le cluster aura du mal à satisfaire les besoins des autres opérations.
Il est important de dimensionner les noeuds pour que les processeurs deviennent les facteurs limitants, bien plus que les disques ou le réseau.
La valeur par défaut de 2Mo.
[DB]BackupMemoryCe paramètre est simplement la somme des deux précédents :
BackupDataBufferSizeetBackupLogBufferSize.La valeur par défaut de 4Mo.
[DB]BackupWriteSizeCe paramètre spécifie la taille des messages d'écriture sur le disque, pour le log, ainsi que le buffer utilisé pour les sauvegardes.
La valeur par défaut de 32ko.
La section [API] (et son alias
[MYSQLD]) définit le comportement du
serveur MySQL. Aucun paramètre n'est obligatoire. Si aucun
ordinateur ou nom d'hôte n'est fourni, alors tous les hôtes
pourront utiliser ce noeud.
[API]IdCet identifiant est celui du noeud, qui sert comme adresse pour les messages internes du cluster. C'est un entier compris entre 1 et 63. Chaque noed du cluster doit avoir une identité distincte.
[API]ExecuteOnComputerCette valeur fait référence à un des ordinateurs défini dans la section computer.
[API]ArbitrationRankCe paramètre sert à définir les noeuds qui jouent le rôle d'arbitre. Les noeuds MGM et les noeuds API peuvent être des arbitres. 0 signifie qu'il n'est pas utilisé comme arbitre, 1 est la priorité haute, et 2 la priorité basse. Une configuration normale utilise un serveur de gestion comme arbitre, en lui donnant un ArbitrationRank de 1 (ce qui est le défaut), et en mettant tous les noeuds API à 0 (ce n'est pas le comportement par défaut en MySQL 4.1.3).
[API]ArbitrationDelayEn donnant une valeur différente de 0 à cette option, le serveur de gestion va retarder ses réponses d'arbitrage. Par défaut, le délai est nul, et c'est très bien comme cela.
[API]BatchByteSizePour les requêtes qui deviennent des analyses complètes de table ou des analyses d'intervalle, il est important pour les performances de lire les lignes par groupe. Il est possible de configurer la taille de ce groupe en terme de nombre de lignes et de taille de données (en octets). La taille réelle du groupe sera limité par les deux paramètres.
La vitesse des requêtes peut varier de près de 40% en fonction de la valeur de ce paramètre. Dans les versions futures, le serveur MySQL fera les estimations nécessaires pour configurer ces paramètres lui-même.
Ce paramètre est mesuré en octets, et par défaut, il vaut 32KB.
[API]BatchSizeCe paramètre est le nombre de lignes et il vaut par défaut 64. La valeur maximale est 992.
[API]MaxScanBatchSizeLa taille du groupe est la taille de chaque groupe envoyé par chaque noeud de stockage. La plupart des analyses sont effectuées en paralelle : pour protéger le serveur MySQL d'un afflux monstrueux de données, ce paramètre permet de limiter le nombre total de groupe sur tous les noeuds.
La valeur par défaut de ce paramètre est de 256Ko. Sa taille maximale est 16Mo.
TCP/IP est le mécanisme de transport par défaut pour établir des connexions dans le cluster MySQL. Il n'est pas nécessaire de définir une connexion, car il y aura une connexion automatique entre chaque noeud de stockage, entre chaque noeud MySQL et un noeud de stockage, et entre chaque noeud de gestion et les noeuds de stockage.
Il est uniquement nécessaire de définir une connexion que si
vous devez modifier les valeurs par défaut de la connexion.
Dans ce cas, il est nécessaire de définir au moins
NodeId1, NodeId2 et les
paramètres modifiés.
Il est aussi possible de modifier les valeurs par défaut en
modifiant les valeurs de la section [TCP
DEFAULT].
[TCP]NodeId1,[TCP]NodeId2Pour indentifier une connexion entre deux noeuds, il est nécessaire de fournir un identifiant de noeud pour chacun d'entre eux dans
NodeId1etNodeId2.[TCP]SendBufferMemoryLe transporteur TCP utilise un buffer pour tous les messages avant de les transférer au système d'exploitation. Lorsque le buffer atteind 64ko, il est envoyé. Le buffer est aussi envoyé lorsque les messages ont été exécuté. Pour gérer les situations temporaires de surcharge, il est possible de définir un sur-buffer. La taille par défaut de ce buffer est 256ko.
[TCP]SendSignalIdPour être capable de suivre le diagramme de message distribué, il est nécessaire d'identifier chaque message avec un marqueur. En activant ce paramètre, le marqueur sera aussi transféré sur le réseau. Cette fonctionnalité n'est pas activée par défaut.
[TCP]ChecksumCe paramètre est aussi une paramètre Y/N (oui/non), qui n'est pas activé par défaut. Lorsqu'il est activé, tous les messages sont munis d'une somme de contrôle avant d'être envoyés au buffer. Les vérifications contre les corruptions sont aussi renforcées.
[TCP]PortNumberCeci est le numéro de port à utiliser pour attendre les connexions des autres noeuds. Ce pot doit être spécifié dans la section
[TCP DEFAULT].Ce paramètre ne doit plus être utilisé. Utilisez plutôt le paramètre ServerPort sur les noeuds de stockage.
[TCP]ReceiveBufferMemoryCe paramétre spécifie le taille du buffer utilisé lors de la reception des données dans la socket TCP/IP. Il y a peu de raison pour modifier ce paramètre, dont la valeur par défaut est 64ko. Il permettrait uniquement d'économiser de la mémoire.
Les segments de mémoire partagées sont supportées
uniquement pour certaines compilations spécifiques du cluster
MySQL, avec l'option de configure
--with-ndb-shm. Son implémentation va
sûrement évoluer. Lorsque vous définissez un segment de
mémoire partagée, il est nécessaire de définir au moins
NodeId1, NodeId2 et
ShmKey. Tous les autres paramètres ont des
valeurs par défaut qui fonctionneront dans la plupart des
cas.
[SHM]NodeId1,[SHM]NodeId2Pour identifier une connexion entre deux noeuds, il est nécessaire de fournir l'identitité des deux noeuds dans
NodeId1etNodeId2.[SHM]ShmKeyLors de la configuration de segments de mémoire partagée, un identifiant est utilisé pour définir de manière unique le segment à utiliser pour les communications. C'est un entier qui n'a pas de valeur par défaut.
[SHM]ShmSizeChaque connexion a un segment de mémoire où les messages ont été stockés par l'envoyeur, et lus par le lecteur. Ce segment a une taille défini par ce paramètre. Par défaut, il vaut 1Mo.
[SHM]SendSignalIdPour être capable de suivre le diagramme de message distribué, il est nécessaire d'identifier chaque message avec un marqueur. En activant ce paramètre, le marqueur sera aussi transféré sur le réseau. Cette fonctionnalité n'est pas activée par défaut.
[SCI]ChecksumCe paramètre est aussi une paramètre Y/N (oui/non), qui n'est pas activé par défaut. Lorsqu'il est activé, tous les messages sont munis d'une somme de contrôle avant d'être envoyés au buffer. Les vérifications contre les corruptions sont aussi renforcées.
Les transporteurs SCI sont des connexions entre noeuds dans un
cluster MySQL, si ce dernier a été compilé avec l'option
--with-ndb-sci=/your/path/to/SCI de la
commande configure. Le chemin doint pointer
sur le dossier qui contient les bibliothèques SCI et leurs
fichiers d'entête.
Il est fortement recommandé d'utiliser les transporteurs SCI pour les communications entre les noeuds ndbd. De plus, utiliser les transporteurs SCI signifie que les processus ndbd ne seront jamais inactifs : utilisez ces transporteurs sur des machines qui ont au moins 2 processeurs, donc un est dédiés à ndbd. Il faut au moins un processeur par processus ndbd, et un autre pour gérer les activités du système d'exploitation.
[SCI]NodeId1,[SCI]NodeId2Pour indentifier une connexion entre deux noeuds, il est nécessaire de fournir un identifiant de noeud pour chacun d'entre eux dans
NodeId1etNodeId2.[SCI]Host1SciId0Identifie le noeud SCI du premier noeud identifié par NodeId1.
[SCI]Host1SciId1Il est possible de configurer les transporteurs SCI avec reprise sur incident entre deux cartes SCI qui utilisent deux réseaux distincts. Ce paramètre identifie l'identifiant de noeud et la seconde carte à utiliser sur le premier noeud.
[SCI]Host2SciId0Identifie le noeud SCI du premier noeud identifié par NodeId2.
[SCI]Host2SciId1Il est possible de configurer les transporteurs SCI avec reprise sur incident entre deux cartes SCI qui utilisent deux réseaux distincts. Ce paramètre identifie l'identifiant de noeud et la seconde carte à utiliser sur le second noeud.
[SCI]SharedBufferSizeChaque transporteur dispose d'un segment de mémoire partagée entre deux noeuds. Avec ce segment de taille par défaut 1Mo, la plupart des applications seront satisfaites. Les tailles inférieures, vers 256 ko posent des problèmes pour les insertions simultanées. Si le buffer est trop petit, il peut conduire à des crash de ndbd.
[SCI]SendLimitUn petit buffer devant le media SCI temporise les messages avant de les envoyer sur le réseau SCI. Par défaut, sa taille est de 8 ko. La plupart des tests de vitesse montrent que l'amélioration de vitesse est la meilleure à 64 ko mais que 16ko arrive presque au même résultat : il n'y avait plus de diférence mesurable après 8ko au niveau du Cluster.
[SCI]SendSignalIdPour être capable de suivre le diagramme de message distribué, il est nécessaire d'identifier chaque message avec un marqueur. En activant ce paramètre, le marqueur sera aussi transféré sur le réseau. Cette fonctionnalité n'est pas activée par défaut.
[SCI]ChecksumCe paramètre est aussi une paramètre Y/N (oui/non), qui n'est pas activé par défaut. Lorsqu'il est activé, tous les messages sont munis d'une somme de contrôle avant d'être envoyés au buffer. Les vérifications contre les corruptions sont aussi renforcées.
Il y a quatre processus à bien connaître lorsque vous utilisez le cluster MySQL. Nous allons voir leur fonctionnement, et leurs options.
mysqld est le processus traditionnel du serveur MySQL. Pour être utilisé avec MySQL Cluster, il doit être compilé avec le support des tables NDB. Si le binaire mysqld a été compilé correctement, le moteur de tables NDB Cluster est désactivé par défaut.
Pour activer le moteur NDB, il y a deux méthodes. Soit vous
utilisez l'option --ndbcluster au démarrage,
lorsque vous utilisez la commande mysqld ou
bien, insérez une ligne avec ndbcluster dans
la section [mysqld] de votre fichier
my.cnf.
Un moyen facile pour vérifier que votre serveur supporte le
moteur NDB Cluster est d'utiliser la commande
SHOW ENGINES depuis un client
mysql. Vous devriez voir la valeur
YES dans la ligne de
NDBCLUSTER. Si vous voyez
NO, c'est que vous n'utilisez pas le
programme mysqld compilé avec le support de
NDB Cluster. Si vous voyez
DISABLED, alors vous devez simplement activer
le moteur dans votre fichier de configuration
my.cnf.
Le serveur MySQL doit savoir comment lire la configuration du cluster. Pour accéder à cette configuration, il doit connaître 3 choses :
Son propre numéro d'identifiant de noeud dans le cluster.
Le nom d'hôte ou l'adresse IP où le serveur de gestion réside.
Le port sur lequel se connecter au serveur de gestion.
L'identifiant peut être omis en MySQL version 4.1.5 et plus récent, car les identifiants de noeuds sont dynamiquement alloués.
Il y a actuellement trois moyens pour donner ces informations au
processus mysqld. La méthode recommandée
est de spécifier la chaîne de connexion de
mysqld appelée
ndb-connectstring, soit au démarrage de
mysqld ou dans le fichier
my.cnf. Vous pouvez aussi inclure cette
information dans un fichier appelé
Ndb.cfg. Ce fichier doit résider dans le
dossier de données de MySQL. Une autre solution est de
configurer la variable d'environnement appelée
NDB_CONNECTSTRING. La chaîne sera la même
dans tous les cas :
"[nodeid=<id>;][host=]<host>:<port>".
Si aucune information n'est fournie, cette chaîne vaudra par
défaut "host=localhost:2200".
shell> mysqld --ndb-connectstring=ndb_mgmd.mysql.com:2200
ndb_mgmd.mysql.com est l'hôte où le serveur
de gestion réside : il attend sur le port 2200.
Avec cette configuration, le serveur MySQL sera partie prenant du cluster MySQL, et accédera à la liste complète de tous les noeuds du cluster ainsi que leur statut. Il va se connecter à tous les noeuds de stockage, et sera capable d'utiliser chacun d'entre eux comme coordonnateur de transaction, ainsi que pour accéder aux données.
ndbd est le processus qui gère les données dans les tables basées sur lem oteur NDB Cluster. C'est ce processus qui contient la logique de gestion des transactions distribuées, la restauration des noeuds, la pose des jalons sur le disque, la sauvegarde en ligne, et de nombreuses autres fonctionnalités.
Dans un cluster, il y a un groupe de processus ndbd qui coopèrent pour gérer les données. Ces processus peuvent s'exécuter sur la même machine ou sur des ordinateurs différents, de manière complètement configurable.
Avant MySQL version 4.1.5, le processus ndbd se lancerait dans un dossier différent. La raison à cela est que ndbd génère son propre jeu de log dans le dossier de démarrage.
Depuis MySQL 4.1.5, cela a été modifié pour que les fichiers
soient placés dans un dossier spécifié par
DataDir dans le fichier de configuration.
ndbd peut maintenant être lancé depuis
n'importe où.
Ces fichiers de logs sont les suivants (le 2 est l'identifiant de noeud).
ndb_2_error.log(anciennementerror.logen version 4.1.3) est le fichier qui contient les informations sur tous les plantages que ndbd a rencontré, et un message d'erreur court ainsi qu'un référence vers le fichier de trace pour le dernier crash. Une telle ligne peut être :Date/Time: Saturday 31 January 2004 - 00:20:01 Type of error: error Message: Internal program error (failed ndbrequire) Fault ID: 2341 Problem data: DbtupFixAlloc.cpp Object of reference: DBTUP (Line: 173) ProgramName: NDB Kernel ProcessID: 14909 TraceFile: ndb_2_trace.log.2 ***EOM***
ndb_2_trace.log.1(anciennementNDB_TraceFile_1.traceen version 4.1.3) est un fichie de trace, décrivant exactement ce qui est arrivé avant l'erreur. Cette information est utile pour l'équipe d'administration du cluster MySQL. Les informations de ce fichier sont décrites dans la sectionMySQL Cluster Troubleshooting. Le nombre de fichier de trace est configurable, de manière a maîtriser l'écrasement des anciens fichiers par les nouveaux. 1, dans ce contexte, est le numéro du fichier de trace.ndb_2_trace.log.next(anciennementNextTraceFileNo.logen version 4.1.3) est le fichier qui garde trace du prochain numéro de fichier de trace.ndb_2_out.logest le fichier qui contient les données affichées par le processus ndbd. 2, dans ce contexte, est l'identifiant de noeued. Ce fichier n'existe que si ndbd est lancé en mode démon, ce qui est le défaut en 4.1.5; anciennementnode2.outen version 4.1.3)ndb_2.pidest le fichier qui contient l'identifiant de processus lorsquendbdest lancé en mode démon (c'est le comportement par défaut depuis la version 4.1.5 et s'appellaitnode2.piden version 4.1.3). Il fonctionne aussi comme un verrou, pour éviter de lancer des noeuds avec le même identifiant.ndb_2_signal.log(anciennementSignal.logen version 4.1.3) est le fichier qui ne sert que pour les versions de déguage de ndbd : il est alors possible de suivre les messages entrants, sortants et internes dans le processus ndbd.
Il est recommandé de ne pas utiliser de dossier monté en NFS car dans certains environnement, il y a des problèmes de verrouillages sur le fichier de PID, même si le processus s'est arrêté.
De même, lorsque vous lancez le processus
ndbd, il peut être nécessaire de spécifier
le nom d'hôte du serveur de gestion ainsi que son port.
Optionnellement, il faut aussi ajouter le numéro
d'identification de noeud. Encore une fois, il y a trois fa¸ons
de spécifier ces informations. Soit une chaîne de connexion
qui doit être stockée dans le fichier
Ndb.cfg, et ce fichier doit être stocké
dans le dossier de démarrage de ndbd. La
seconde option est de configurer la variable d'environnement
NDB_CONNECTSTRING avant le démarrage du
processus. La troisième option est d'utiliser la ligne de
commande et l'option ci-dessous. Voyez les sections
précédentes pour connaître le format exact de la chaîne.
shell> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:2200"
Lorsque ndbd se lance, il va lancer en fait 2 processus. Le processus de lancement s'appelle "angel" et sa seule tâche est de surveiller la fin du processus d'exécution, et de relancer le processus ndbd s'il est configuré pour cela. Par conséquent, si vous tentez de terminer ndbd avec la commande kill d'Unix, il sera nécessaire de terminer les deux processus. Une solution plus élégante pour gérer la terminaison des processus ndbd est d'utiliser le client de gestion et d'arrêter les processus depuis ce client.
Le processus d'exécution utilise un thread pour toute ses activités de lecture, écriture et analyse des données, ainsi que pour ses autres activités. Ce thread est con¸u pour être asynchrone, et gérer facilement des milliers d'actions simultanées. En plus, il y a un garde-fou qui supervise le thread d'exécution, pour s'assurer que ce dernier ne se bloque pas dans une boucle infinie ou dans un autre problème du même genre. Il y a un pool de thread qui assurent les entrées/sorties. Chaque thread gère un fichier. En plus, d'autres threads peuvent être utilisés pour les activités de transport du processus ndbd. Par conséquent, un processus qui effectue un grand nombre d'activités, verra le processus ndbd utiliser 2 processeurs, s'il en a la possibilité. Sur une machine avec de nombreux processeurs, il est recommandé d'utiliser plusieurs processus ndbd, qui seront configurés pour représente différents groupes de noeuds.
Le serveur de gestion est le processus qui lit le fichier de configuration du cluster, et distribue cette information à tous les noeuds qui le demande. Il gère aussi le log d'activité du cluster. Les clients de gestion s'y connectent et peuvent l'utiliser pour envoyer des commandes d'analyse et d'administration.
Depuis MySQL version 4.1.5, il n'est plus nécessaire de spécifier une chaîne de connexion lors du démarrage du serveur. Si vous utilisez plusieurs serveurs de gestion, une chaîne de connexion doit être fournie, et tous les noeuds du cluster doivent explicitement spécifier leur identifiant.
Les fichiers suivants sont créés ou utilisés par
ndb_mgmd dans son dossier de démarrage de
ndb_mgmd. Depuis MySQL version 4.1.5, les
fichiers de log et de PID seront placés dans le dossier de
données DataDir specifié dans le fichier de
configuration :
config.iniest le fichier de configuration du cluster. Il est créé par l'utilisateur et lu par le serveur de gestion. Comment écrire ce fichier est décrit dans la section Section 16.4, « Configuration de MySQL Cluster ».ndb_1_cluster.log(anciennementcluster.logen version 4.1.3) est le fichier où les événements du cluster sont consignés. Les événements du cluster sont, par exemple : les jalons commencés ou complétés, les incidents de noeuds, les démarrages de noeuds, les niveaux d'utilisation de mémoire, etc. Les événements rapportés sont décrits dans la section Section 16.6, « Administration de MySQL Cluster ».ndb_1_out.log(anciennementnode1.outen version 4.1.3) est le fichier utilisé pour les entrées et sorties (stdout et stderr) lors de l'exécution du serveur de gestion comme démon. 1, dans ce contexte, est l'identifiant de noeud.ndb_1.pid(anciennementnode1.piden version 4.1.3) est le fichier de PID utilisé lors de l'exécution du serveur de gestion comme démon. 1, dans ce contexte, est l'identifiant de noeud.ndb_1_cluster.log.1(anciennementcluster.log.1en version 4.1.3), lorsque le log de cluster dépasse un millions d'octets, alors le fichier de log prend le nom indiqué ici, où 1 est le nombre de fichier de logs : si 1, 2 et 3 existent déjà, le suivant sera le numéro 4.
Le dernier processus important à connaître est le client de gestion. Ce processus n'est pas nécessaire pour faire fonctionner le cluster. Son intérêt est que pouvoir vérifier le statut du cluster, de lancer les sauvegardes, et effectuer les autres activités d'administration. Il fournit un moyen d'accès et un jeu de commandes.
En fait, le client de gestion utilise une interface C qui donne l'accès au serveur de gestion : pour les utilisateurs experts, il est possible de programmer des processus spécifiques qui pourront effectuer des taches d'administration automatisées.
Lorsque vous lancez le client de gestion, il est nécessaire d'indiquer le nom d'hôte et le port du serveur de gestion, comme dans l'exemple ci-dessous. Par défaut, c'est l'hôte local et le port 2200.
shell> ndb_mgm localhost 2200
--ndbclusterSi le binaire supporte le moteur de table
NDB Cluster, le comportement par défaut est de désactiver son support. Vous pouvez changer ce comportement avec cette option. Utiliser le moteurNDB Clusterest obligatoire pour pouvoir utiliser MySQL Cluster.--skip-ndbclusterDésactive le moteur de table
NDB Cluster. C'est le comportement par défaut pour les applications où il est inclut. Cette option peut s'appliquer uniquement si le serveur a été configuré pour utiliser le moteur de tableNDB Cluster.--ndb-connectstring=connect_stringLorsque de l'utilisation du moteur de table
NDB, il est possible de désigner le serveur de gestion qui distribue les configurations du cluster en lui assignant une chaîne de connexion.
-?, --usageCes options ne font qu'afficher l'aide du programme.
-cconnect_string, --connect-stringconnect_stringPour ndbd, il est aussi possible de spécifier la chaîne de connexion au serveur de commande, sous forme d'option.
shell>
ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:2200"-d, --daemonIndique à ndbd qu'il doit s'exécuter comme démon. Depuis MySQL version 4.1.5, c'est le comportement par défaut.
--nodaemonIndique à ndbd qu'il ne doit pas se lancer comme un démon. C'est pratique lors du déboguage de ndbd et que vous voulez avoir l'affichage des résultats du programme.
--initialDemande à ndbd de faire un démarrage initial. Un démarrage initial efface tous les fichiers créés par d'anciens ndbd durant la restauration. Il va aussi créer le fichier de log de restauration, ce qui peut prendre beaucoup de temps sur certains systèmes d'exploitation.
Un démarrage initial ne sert qu'au tout premier démarrage du processus ndbd. Il supprime tous les fichiers du système de fichiers, et crée tous les fichiers de log REDO. Lorsque vous faites une mise à jour logicielle qui modifie le contenu de ces fichiers, il est aussi nécessaire d'utiliser cette option au redémarrage de ndbd. Enfin, cette option peut être utile en dernier recours, si votre système d'arrive pas à redémarrer. Dans ce cas, soyez conscients que détruire le contenu du système de fichiers signifie que ce noeud ne peut plus être utilisé pour restaurer des données.
Cette option n'affecte pas les fichiers de sauvegarde créés.
L'ancienne fonctionnalité représentée par
-ipour cette option a été supprimée pour s'assurer qu'elle n'est pas confondue avec celle-ci par mégarde.--nostartIndique à ndbd de ne pas démarrer automatiquement. ndbd va se connecter au serveur de gestion, obtiendra le fichier de configuration, et initialisera les communications avec les noeuds. Mais il ne va pas lancer le moteur d'exécution jusqu'à ce qu'il en re¸oive l'ordre manuel du serveur de gestion. Le serveur de gestion peut émettre cette commande sur ordre du client de gestion.
-v, --versionAffiche le numéro de version du processus ndbd. Le numéro de version est celui du cluster MySQL. Il est important car au momment du lancement du cluster, MySQL vérifie si les versions des serveurs des noeuds peuvent cohabiter dans le cluster. Il est aussi important durant les mises à jour logicielles du cluster (voyez la section
Software Upgrade of MySQL Cluster).--debug=optionsCette option peut être utilisée avec les versions compilées en mode déboguage. Elle sert à activer l'affichage des appels de déboguage, de la même manière que pour mysqld.
-? --usageAffiche une déscription rapide des options disponibles.
-?, --usageCes options font afficher l'aide du programme.
-cfilename--config-file=filenameIndique au serveur de gestion quelle fichier de configuration utiliser. Cette option est obligatoire. Le nom par défaut du fichier est
config.ini.-d --daemonIndique au client ndb_mgmd de se lancer sous forme de démon. C'est le comportement par défaut.
-nodaemonIndique au serveur de gestion de ne pas se lancer comme un démon.
-v --versionAffiche le numéro de version du serveur de gestion. Le numéro de version est celui du cluster MySQL. Le serveur de gestion peut s'assurer que seules les versions compatibles avec lui sont acceptées et utilisées dans le cluster.
--debug=optionsCette option ne peut être utilisée que dans les versions compilées en mode déboguage. Elle est utilisée pour afficher plus d'informations de fonctionnement et accepter les appels de fonctions de déboguages de mysqld.
-?, --usageCes options ne font qu'affficher l'aide du programme.
[host_name[port_num]]Pour lancer le client de gestion, il est nécessaire de spécifier où le serveur de gestion réside. Cela signifie qu'il faut spécifier le nom d'hôte et le port de communication. Par défaut, l'hôte est
localhostet le port par défaut est 2200.--try-reconnect=numberSi la connexion au serveur de gestion se perd, il est possible de spécifier le nombre de tentatives avant de conclure à une erreur. Par défaut, le client va réessayer toutes les 5 secondes jusqu'à ce qu'il réussisse.
Gérer une cluster MySQL implique différentes opérations. La première est celle de configurer et de démarrer le cluster MySQL : elle est couverte par les sections Section 16.4, « Configuration de MySQL Cluster » et Section 16.5, « Serveur de gestion du cluster MySQL ». Cette section couvre la gestion d'un cluster MySQL en fonctionnement.
Il y a essentiellement deux moyens pour gérer activement un
cluster MySQL en fonctionnement. La première est l'utilisation
des commandes dans le client de gestion, qui surveille le statut
du cluster, les niveaux de logs, les sauvegardes en cours et les
noeuds qui peuvent être arrêtés ou relancés. La seconde
méthode utilise le résultat du log du cluster. Le log du cluster
est envoyé dans le fichier ndb_2_cluster.log
dans le dossier DataDir du serveur de gestion.
Le log du cluster contient les rapports d'événements du moteur
ndbd et de ses processus dans le cluster. Il
est possible aussi d'envoyer le log dans le log système Unix.
En plus du fichier de configuration central, le cluster peut aussi être contrôlé avec une interface en ligne de commande. La ligne de commande est disponible via un processus séparé de client de gestion du cluster. C'est l'interface principale de gestion du cluster.
Le client de gestion a les commandes suivantes de base.
Ci-dessous, <id> indique un noeud de
base de données (i.e. 21) ou le mot clé ALL
qui indique que la commande doit être appliquée à tous les
noeuds dans le cluster.
HELPAffiche les informations sur toutes les commandes disponibles.
SHOWAffiche les informations sur le statut du cluster.
<id> STARTLance le noeud de base de données identifié par
<id>, ou bien tous les noeuds.<id> STOPStoppe le noeud de base de données identifié par
<id>, ou bien tous les noeuds.<id> RESTART [-N] [-I]Relance le noeud de base de données identifié par
<id>, ou bien tous les noeuds.<id> STATUSAffiche les informations de statut du noeud de base de données identifié par
<id>(ou de tous les noeuds avecALL).ENTER SINGLE USER MODE <id>Active le mode d'utilisateur unique, où seule l'API avec le noeud
<id>est autorisée pour accéder au système de base de données.EXIT SINGLE USER MODEQuitte le mode d'utilisateur unique.
QUITQuitte le client de gestion du cluster.
SHUTDOWNArrête tous les noeuds du cluster, hormis les serveurs MySQL, puis s'arrête.
Les commandes des logs d'événements sont listées dans la prochaine section, et les commandes de sauvegarde sont données dans une section séparée.
Le cluster MySQL a deux logs d'événements : le log de cluster et le log de noeuds.
Le log de cluster est un log pour le cluster entier, et il peut avoir différentes destinations (fichiers, console du serveur de gestion, ou log système).
Le log de noeuds est un log local à chaque noeud, et il est envoyé vers la console. Les deux logs peuvent être configurés pour recevoir des sous-ensembles de tous les événements.
Note : le log du cluster est le log recommandé. Le log de noeud ne sert que pour le développement d'application ou le déboguage.
Chaque événenement a les propriétés suivantes :
Categorie (STARTUP, SHUTDOWN, STATISTICS, CHECKPOINT, NODERESTART, CONNECTION, ERROR, INFO)
Priorité (1-15 où 1 est le plus important, et 15 le moins important)
Severité (ALERT, CRITICAL, ERROR, WARNING, INFO, DEBUG)
Les deux logs (celui du cluster et celui du noeud) peuvent être filtrés en fonction de ces propriétés.
Les commandes suivantes sont liées au log du cluster :
CLUSTERLOG ONActivation du log du cluster
CLUSTERLOG OFFDésactivation du log du cluster.
CLUSTERLOG INFOInformatins sur la configuration du log.
<id> CLUSTERLOG <category>=<threshold>Enregistre les catégories d'événements ayant une priorité inférieure ou égale au seuil indiqué, dans le log du cluster.
CLUSTERLOG FILTER <severity>Active/désactive l'enregistrement des types de sévérités indiquées.
La table suivante décrit les configurations par défaut pour tous les noeuds de bases de données dans le cluster. Si un événement a une priorité dont la valeur est inférieure ou égale à seuil de priorité, il est alors enregistré dans le log du cluster.
Notez que les événements sont rapportés pour chaque noeud de base de donneés, et que les seuils peuvent être différents sur chaque noeud.
| Catégorie | seuil par défaut (toutes les bases) |
| STARTUP | 7 |
| SHUTDOWN | 7 |
| STATISTICS | 7 |
| CHECKPOINT | 7 |
| NODERESTART | 7 |
| CONNECTION | 7 |
| ERROR | 15 |
| INFO | 7 |
Un seuil permet de filtrer les événements par catégorie.
Par exemple, un événement STARTUP avec
une priorité de 3 n'est jamais émis à moins que le seuil de
STARTUP ne soit changé à 3 ou plus bas.
Seuls les événements avec des priorités de 3 ou plus bas
sont émis si le seuil est de 3. Les sévérité
d'événements correspondent aux niveaux du log système
d'UNIX. Ce sont :
| 1 | ALERT | Un problème qui doit être corrigé immédiatement, comme une base de données corrompue |
| 2 | CRITICAL | Problèmes critiques, comme une erreur de volume ou un manque de ressources |
| 3 | ERROR | Problème qui doivent être corrigés, comme un problème de configuration |
| 4 | WARNING | Problèmes qui ne sont pas des erreurs, mais requiert un traitement |
| 5 | INFO | Message d'information |
| 6 | DEBUG | Messages pour le développement de NDB Cluster |
Les niveaux syslog de LOG_EMERG et
LOG_NOTICE ne sont pas utilisés.
Les sévérités d'événements peuvent être activées ou pas. Si la sévérité est active, alors tous les événements avec une priorité inférieure ou égale au seuil seront enregistrés. Si la sévérité est éteinte, alors aucun événement de cette sévérité ne sera enregistré.
Les commandes suivantes sont liées au log du noeud :
<id> LOGLEVEL <levelnumber>Active le niveau de log pour le processus de base de donnéesid, avec le niveau<levelnumber>.
Tous les événements rapportés sont listés ici.
| Evénements | Catégorie | Priorité | Séverité | Description |
| DB nodes connected | CONNECTION | 8 | INFO | |
| DB nodes disconnected | CONNECTION | 8 | INFO | |
| Communication closed | CONNECTION | 8 | INFO | Connexion aux noeuds API & DB fermée |
| Communication opened | CONNECTION | 8 | INFO | Connexion aux noeuds API & DB fermée |
| Global checkpoint started | CHECKPOINT | 9 | INFO | Début de GCP, i.e., le log REDO est écrit sur le disque |
| Global checkpoint completed | CHECKPOINT | 10 | INFO | GCP terminé |
| Local checkpoint started | CHECKPOINT | 7 | INFO | Début d'une vérification de jalon local, i.e., les données sont écrites sur le disque. LCP Id et GCI Id |
| Local checkpoint completed | CHECKPOINT | 8 | INFO | LCP terminé |
| LCP stopped in calc keep GCI | CHECKPOINT | 0 | ALERT | LCP arrêté! |
| Local checkpoint fragment completed | CHECKPOINT | 11 | INFO | Un LCP sur un fragment a été terminé |
| Report undo log blocked | CHECKPOINT | 7 | INFO | Le log d'annulation est bloqué car le buffer est presque plein |
| DB node start phases initiated | STARTUP | 1 | INFO | NDB Cluster démarre |
| DB node all start phases completed | STARTUP | 1 | INFO | NDB Cluster démarré |
| Internal start signal received STTORRY | STARTUP | 15 | INFO | Signal intern pour bloquer la reception après la fin du redémarrage |
| DB node start phase X completed | STARTUP | 4 | INFO | La phase de démarrage est finie |
| Node has been successfully included into the cluster | STARTUP | 3 | INFO | Le noeud président, le noeud courant et l'identifiant dynamique sont affichés |
| Node has been refused to be included into the cluster | STARTUP | 8 | INFO | |
| DB node neighbours | STARTUP | 8 | INFO | Affichage des noeuds voisins à gauche et à droite |
| DB node shutdown initiated | STARTUP | 1 | INFO | |
| DB node shutdown aborted | STARTUP | 1 | INFO | |
| New REDO log started | STARTUP | 10 | INFO | GCI garde X, dernier jalon accessible GCI Y |
| New log started | STARTUP | 10 | INFO | Log termine X, démarre MB Y, stoppe MB Z |
| Undo records executed | STARTUP | 15 | INFO | |
| Completed copying of dictionary information | NODERESTART | 8 | INFO | |
| Completed copying distribution information | NODERESTART | 8 | INFO | |
| Starting to copy fragments | NODERESTART | 8 | INFO | |
| Completed copying a fragment | NODERESTART | 10 | INFO | |
| Completed copying all fragments | NODERESTART | 8 | INFO | |
| Node failure phase completed | NODERESTART | 8 | ALERT | Indique un échec de noeud |
| Node has failed, node state was X | NODERESTART | 8 | ALERT | Indique qu'un noeud a échoué |
| Report whether an arbitrator is found or not | NODERESTART | 6 | INFO | 7 résultats différents |
| - Président relance le thread d'arbitrage [state=X] | ||||
| - Préparation de l'arbitrage, noeud X [ticket=Y] | ||||
| - Re¸oit l'arbitrage, noeud X [ticket=Y] | ||||
| - Démarre l'arbitrage X [ticket=Y] | ||||
| - Perte de l'arbitrage, noeud X - echec de traitement [state=Y] | ||||
| - Perte de l'arbitrage, noeud X - fin de traitement [state=Y] | ||||
| - Perte de l'arbitrage, noeud X <error msg>[state=Y] | ||||
| Report arbitrator results | NODERESTART | 2 | ALERT | 8 résultats différents |
| - Arbitrage perdu - moins de la moitié des noeuds dispo | ||||
| - Arbitrage gagné - majorité du groupe de noeuds | ||||
| - Arbitrage perdu - plus de groupe de noeuds | ||||
| - Partage du réseau - arbitrage demandé | ||||
| - Arbitrage gagné - réponse positive du noeud X | ||||
| - Arbitrage persu - réponse négative du noeud X | ||||
| - Partage du réseau - pas d'arbitre disponible | ||||
| - Partage du réseau - par d'arbitre configuré | ||||
| GCP take over started | NODERESTART | 7 | INFO | |
| GCP take over completed | NODERESTART | 7 | INFO | |
| LCP take over started | NODERESTART | 7 | INFO | |
| LCP take completed (state = X) | NODERESTART | 7 | INFO | |
| Report transaction statistics | STATISTICS | 8 | INFO | nombre de transactions, archivages, lectures, lectures simples, écritures, opérations simultanées, attributs, annulations |
| Report operations | STATISTICS | 8 | INFO | nombre d'opérations |
| Report table create | STATISTICS | 7 | INFO | |
| Report job scheduling statistics | STATISTICS | 9 | INFO | Statistiques internes de programmation de tâches |
| Sent # of bytes | STATISTICS | 9 | INFO | Moyenne de nombre d'octets envoyés au noeud X |
| Received # of bytes | STATISTICS | 9 | INFO | Moyenne de nombre d'octets re¸us au noeud X |
| Memory usage | STATISTICS | 5 | INFO | Utilisation de la mémoire pour les données et les index(80%, 90% et 100%) |
| Transporter errors | ERROR | 2 | ERROR | |
| Transporter warnings | ERROR | 8 | WARNING | |
| Missed heartbeats | ERROR | 8 | WARNING | Le noeud X a raté une pulsation # Y |
| Dead due to missed heartbeat | ERROR | 8 | ALERT | Le noeud X est déclaré mort à cause des pulsations manquées |
| General warning events | ERROR | 2 | WARNING | |
| Sent heartbeat | INFO | 12 | INFO | Pulsation envoyée au noeud X |
| Create log bytes | INFO | 11 | INFO | Partie de log, fichier de log, taille |
| General info events | INFO | 2 | INFO |
Un événement a le format suivant dans le log :
<date & time in GMT> [<any string>] <event severity> -- <log message> 09:19:30 2003-04-24 [NDB] INFO -- Node 4 Start phase 4 completed
Le mode d'utilisateur unique permet à l'administrateur de restreindre l'accès au système de base de données à une seule application (un noeud API). Lorsque vous passez en mode utilisateur unique, toutes les connexions aux noeuds d'API seront refermées et aucune transaction ne sera autorisée. Toutes les transactions en cours sont annulées.
Lorsque le cluster entre en mode d'utilisateur unique (utilisez la commande de statut pour voir si l'état est activé), seul le noeud autorisé dispose d'un accès à la base de données.
Exemple :
ENTER SINGLE USER MODE 5
Après avoir exécuté cette commande, et après que le cluster soit entrée en mode d'utilisateur unique, le noeud d'API d'identifiant 5 devient le seul utilisateur du cluster.
Le noeud spécifié dans la commande ci-dessus doive être un noeud MySQL. Toute tentative de spécifier un autre type de noeud sera rejetée.
Note : si le noeud avec l'identifiant 5 est exécuté avec le
mode ENTER SINGLE USER MODE 5, toutes les
transactions du noeud 5 seront annulées, les connexions
fermées et le serveur devra redémarrer.
La commande EXIT SINGLE USER MODE fait passer
le cluster de mode ``single user mode'' à
``started''. Les serveur MySQL en attente de
connexion seront autorisés à se connecter. Le serveur
identifié comme utilisateur unique sera autorisé à continuer
durant et après la phase de transition.
Exemple :
EXIT SINGLE USER MODE
La meilleure pratique dans le cas des incidents de noeuds en mode d'utilisateur unique est de :
Finir toutes les transactions d'utilisateur unique
Quitter le mode d'utilisateur unique
Redémarrer les noeuds de bases de données
Ou redémarrer les noeuds de bases avant de passer en mode utilisateur unique.
Cette section décrit comment créer une sauvegarde et restaurer ultérieurement une base de données.
Une sauvegarde représente le contenu d'une base de données, à un moment donné. La sauvegarde contient 3 parties principales :
Les méta-données (quelles tables existents, etc.)
Les lignes des tables(les données )
Un historique des transactions archivées
Chaque partie est stockée sur tous les noeuds qui participent à la sauvegarde.
Durant une sauvegarde, chaque noeud sauve ces données sur le disque, en trois fichiers :
BACKUP-<BackupId>.<NodeId>.ctlLe fichier de contrôle, qui contient les données de contrôle et les méta-données.
BACKUP-<BackupId>-0.<NodeId>.dataLe fichier de données qui contient les lignes des tables.
BACKUP-<BackupId>.<NodeId>.logLe fichier de log, qui contient les transactions archivées.
Dans les lignes ci-dessus, <BackupId> est un identifiant pour la sauvegarde, et <NodeId> est l'identifiant du noeud qui a créé le fichier.
Meta data
Les méta-données sont consistuées des définitions de table. Tous les noeuds ont la même définition de table, sauvée sur le disque.
Table records
Les lignes sont sauvées par fragment. Chaque fragment contient un entête qui décrit à quelle table appartient les lignes. Après un groupe de ligne, il y a pied-de-page qui contient une somme de contrôle. Différents noeuds sauvent différents fragment durant la sauvegarde.
Committed log
L'historique contient les transactions archivées, effectuée durant la sauvegarde. Seules les transactions impliquant les tables stockées sur le noeud sont stockées dans le log. Les différents noeuds de la sauvegarde sauvent différents logs, car ils abritent différents fragments de bases de données.
Avant de lancer la sauvegarde, assurez-vous que le cluster est correctement configuré pour les sauvegardes.
Lancez le serveur de gestion.
Exécutez la commande
START BACKUP.Le serveur de gestion vous indiquera ``
Start of backup ordered''. Cela signifie que le serveur de gestion a envoyé la requête au cluster, mais qu'il n'a pas encore re¸u de réponse.Le serveur de gestion va indiquer ``
Backup <BackupId> started'', où <BackupId> est l'identifiant de la sauvegarde. Cette information sera aussi enregistrée dans le log du gluster (à moins que cela ne soit configuré autrement). Cela signifie que le serveur a re¸u des réponses, et que la sauvegarde a été faite. Cela ne signifie pas que la sauvegarde est complète.Le serveur de gestion va indiquer que la sauvegarde est finie avec le message ``
Backup <BackupId> completed''.
Utilisation du serveur pour annuler une sauvegarde :
Lancez le serveur de gestion.
Exécutez la commande
ABORT BACKUP <BACKUPID>. Le numéro <BackupId> est l'identifiant de la sauvegarde, qui est inclut dans la réponse du serveur de gestion au moment de la création de la sauvegarde : ``Backup <BackupId> started''. L'identifiant est aussi sauvé dans le log du cluster (cluster.log).Le serveur de gestion répond ``
Abort of backup <BackupId> ordered''. Cela signifie qu'il a envoyé la requête au cluster, mais n'a pas encore re¸u de réponse.Le serveur de gestion répond ``
Backup <BackupId> has been aborted reason XYZ''. Cela signifie que le cluster a annulé la sauvegarde, et supprimé toutes les ressources reliées, y compris les fichiers.
Notez que s'il n'y a pas de sauvegarde en cours avec
l'identifiant <BackupId> lors de l'annulsation, le
serveur de gestion ne répondra rien du tout. Cependant, une
ligne sera enregistére dans le log du cluster mentionnant
``invalid''.
Le programme de restauration est une commande distincte. Il lit les fichiers de sauvegarde créés, et insère les informations dans la base. Le programme de restauration doit être exécuté pour chaque fichiers de sauvegarde, c'est à dire aussi souvent qu'il y a de noeuds dans le cluster au moment de la création de la sauvegarde.
La première fois que vous exécutez le programme de
restauration, vous devez aussi restaurer les méta-données,
c'est à dire créer les tables. Le programme de restauration
sert d'API avec le cluster, et il a donc besoin d'une
connexion libre pour ce faire. Vous pouvez le vérifier avec
la commande SHOW de ndb_mgm. De la même
manière que pour les autres noeuds API, c'est-à-dire
mysqld,le fichier
Ndb.cfg, la variable d'environnement
NDB_CONNECTSTRING ou l'option de démarrage
-c <connectstring> sert à situer le
serveur de gestion. Les fichiers de sauvegarde doivent être
présents dans le dossier indiqué comme argument du
programme. La sauvegarde peut être restaurée vers une base
ayant une configuration différente de celle qui a créé la
sauvegarde. Par exemple, la sauvegarde 12, créées avec deux
noeuds de bases d'identifiants 2 et 3, peut être restaurées
sur un cluster de 4 noeuds. Le programme doit alors être
exécuté 2 fois : une fois pour chaque noeud du cluster où
la sauvegarde a été faite, tel que décrit ci-dessous.
Note : pour une restauration rapide, les données peuvent être relues en paralelle, tant qu'il y a suffisamment de connexion API libres. Notez que les fichiers de données doivent toujours être appliqués avant les logs.
Note : le cluster doit toujours être vide lors du démarrage d'une restauration.
Il y a quatre paramètres de configuration pour la sauvegarde :
BackupDataBufferSize
La quantité de mémoire utilisée pour les buffer avant que les données soient écrites sur le disque.
BackupLogBufferSize
La quantité de mémoire utilisée pour les buffers de logs, avant qu'ils ne soient écrits sur le disque.
BackupMemory
La quantité totale de mémoire allouée pour effectuer les sauvegardes. Cela doit être la somme des deux options précédentes.
BackupWriteSize
La taille des blocs écrits sur le disque. Cela s'applique aussi bien aux buffers de données qu'aux buffers de log.
Si un code d'erreur est retourné lors de la sauvegarde, alors vérifiez s'il y a assez de mémoire allouée pour la sauvegarde (i.e. les paramètres de configuration). Vérifiez aussi s'il y a assez d'espace sur le disque pour tout acceuillir.
Bien avant de concevoir le cluster NDB en 1996, il est apparu que l'un des problème majeur dans l'architecture d'une base de données paralelle est la communication entre les noeuds via un réseau. Par conséquent, dès le début, le cluster NBD a été con¸u pour supporter le concept de transporteur, et pour en supporter différentes sortes.
Actuellement, le code de base inclus 4 transporteurs différents, dont 3 d'entre eux sont déjà fonctinnels. La majorité des utilisateurs exploitent TCP/IP aujourd'hui, via Ethernet, car ces technologies sont disponibles sur toutes les machines. C'est aussi le transporteur le mieux testé du MySQL Cluster.
Chez MySQL, nous travaillons fort pour nous assurer que les communications entre les processus ndbd sont faits avec des paquets aussi gros que possible, car cela profitera à tous les médias de communication : tous les modes de transports gagnent à envoyer des messages de grande taille par rapport à des messages de petite taille.
Pour les utilisateurs qui recherchent les performances absolues, il est aussi possible d'utiliser des interconnexions de cluster pour améliorer encore les performances. Il y a deux moyens pour cela, soit en utilisant un transporteur qui a été con¸u pour cela, soit en utilisant des sockets qui évitent le recours aux piles TCP/IP.
Nous avons fait des expériences avec les variantes de ces techniques, et avec la technologie SCI, développée par Dolphin (www.dolphinics.no).
Dans cette section, nous allons vous montrer comment utiliser un cluster TCP/IP normal avec les sockets SCI. Les pré-requis pour cela est que les machines doivent être capables de communiquer avec des cartes SCI. Cette documentation est basée sur les sockets SCI version 2.3.0, du 1er octobre 2004.
Pour utiliser les sockets SCI, vous pouvez utiliser n'importe quelle version du cluster MySQL. Les tests ont été fait sur la version 4.1.6. Aucune compilation particulière n'est nécessaire, car il utilise les appels normaux aux sockets, ce qui est la configuration de MySQL Cluster. Les sockets SCI ne sont supportées que sur les noyaux Linux 2.4 et 2.6 pour le moment. Les transporteurs SCI fonctionnent sur d'autres systèmes d'exploitation, même si seul Linux 2.4 a été vérifié.
Il y a essentiellement 4 choses nécessaires pour activer les sockets SCI. La première est de compiler les bibliothèques de sockets SCI. La seconde est d'installer les bibliothèques SCI dans le noyau. La troisième est d'installer les fichiers de configuration. Enfin, la bibliothèque SCI du noyau doit être activée pour toute la machine, ou pour le shell d'où le cluster MySQL est lancé. Ce processus doit être répété pour chaque machine du cluster qui utilisera les sockets SCI pour communiquer.
Deux paquets doivent être installés pour faire fonctionner les sockets SCI. Le premier paquet compile les bibliothèques avec lesquelles les bibliothèques SCI sont compilées. Actuellement, la distribution est uniquement au format code source.
Les dernières versions de ces paquets sont actuellement disponibles à :
http://www.dolphinics.no/support/downloads.html
http://www.dolphinics.no/ftp/source/DIS_GPL_2_5_0_SEP_10_2004.tar.gz http://www.dolphinics.no/ftp/source/SCI_SOCKET_2_3_0_OKT_01_2004.tar.gz
La prochaine étape est de décompresser ces dossiers. Les sockets SCI sont décompressées sous le code DIS. Puis, le code de base est compilé. L'exemple ci-dessous montre les commandes utilisées sur Linux/x86 pour ce faire.
shell>tar xzf DIS_GPL_2_5_0_SEP_10_2004.tar.gzshell>cd DIS_GPL_2_5_0_SEP_10_2004/src/shell>tar xzf ../../SCI_SOCKET_2_3_0_OKT_01_2004.tar.gzshell>cd ../adm/bin/Linux_pkgsshell>./make_PSB_66_release
Si la compilation se passe sur une machine Opteron, et doit utiliser l'exention 64 bits, alors utilisez make_PSB_66_X86_64_release à la place. Si la compilation a lieu sur Itanium, utilisez make_PSB_66_IA64_release. Les variantes X86-64 devraient fonctionner pour les architectures Intel EM64T mais aucun test n'est connu pour cela.
Après avoir compilé le code de base, il est placé dans une archive compressée. Il est temps d'installer le paquet au bon endroit. Dans cet exemple, nous allons placer l'installation dans le dossier /opt/DIS. Ces actions vous imposerons de vous identifier comme super-utilisateur.
shell>cp DIS_Linux_2.4.20-8_181004.tar.gz /opt/shell>cd /optshell>tar xzf DIS_Linux_2.4.20-8_181004.tar.gzshell>mv DIS_Linux_2.4.20-8_181004 DIS
Maintenant que les bibliothèques et les binaires sont en place, nous devons nous assurer que les cartes SCI recoivent les bons identifiants de noeuds dans l'espace SCI. Comme SCI est un élément réseau, nous devons commencer par décider de la structure du réseau.
Il y a trois types de structure de réseau : la première est un simple anneau unidimensionnel, le second utilise les hub SCI, avec un anneau par hub, et finalement, il y a des tores 2D et 3D. Chaque type a sa technique pour attribuer les identifiants.
Un anneau simple utilise des identifiant espacés de 4 :
4, 8, 12, ....
La deuxième méthode utilise des hubs. Le hub SCI a 8 ports. Sur chaque port, il est possible de placer un anneau. Il est nécessaire de s'assurer que les anneaux des hubs utilisent des espaces d'identifiants différents. Le premier port utilisera les identifiants inférieurs à 64, et les 64 identifiants suivants seront attribués au prochain port, etc.
4,8, 12, ... , 60 Anneau du premier port 68, 72, .... , 124 Anneau du deuxième port 132, 136, ..., 188 Anneau du troisième port .. 452, 456, ..., 508 Anneau du huitième port
Les structures de réseaux en tore 2D/3D prennent en compte la position de chaque noeud dans chaque dimension. La première dimension est incrémentée de 4, la deuxième de 64 et la troisième de 1024. Regardez dans le dauphin pour plus d'informations dessus.
Durant nos tests, nous avons utilisés des hubs. La majorité des très gros cluster utilisent des installations à Tore 2D/3D. La fonctionnalité supplémentaire que permet les hubs est qu'avec des doubles cartes SCI, nous pouvons facilement construire un réseau redondant, où les erreurs de réseau sont aussitôt reprises en 100 microsecondes. Cette fonctionnalité est supportée par le transporteur SCI, et est actuellement en développement pour les sockets SCI.
La reprise sur échec est aussi possible avec les tores 2D/3D, mais elle impose l'envoie de nouveaux index de routages à tous les noeuds. Cela prend environ 100 milliseconds et sera probablement acceptable pour les situations de haute disponibilité.
En agenceant correctement les noeuds NDB dans l'architecture, il est possible d'utiliser deux hubs pour monter une architecture de 16 ordinateurs interconnectés, sans aucun point d'interruption. Avec 32 ordinateurs et 2 hubs, il est possible de configurer le cluster de telle manière qu'un incident ne perturbera pas plus de 2 noeuds, et dans ce cas, on saura même quelle paire sera touchée. Par conséquent, en pla¸ant ces serveurs dans des groupes NDB séparés, il est possible de construire un cluster MySQL sécurisé. Nous n'entreront pas dans les détails de cette architecture, car seuls ceux qui le souhaitent auront la patience de lire de niveau de détails.
Pour configurer l'identifiant de noeud sur une carte SCI,
utilisez l'une des commandes disponibles dans le dossier
/opt/DIS/sbin. -c 1 fait référence à la
carte SCI, où 1 est son numéro s'il y a une seule carte sur la
machine. Dans ce cas, utilisez toujours l'adapteur 0 (avec -a
0). 68 est l'identifiant de noeud choisi comme exemple :
shell> ./sciconfig -c 1 -a 0 -n 68
Dans ce cas, nous avons plusieurs cartes SCI dans notre machine, et la seule solution sécuritaire pour savoir quelle carte est dans quel emplacement, est d'utiliser la commande suivante :
shell> ./sciconfig -c 1 -gsn
Elle vous retournera le numéro de série de la carte, qui peut être trouvée sur sont dos. Répétez cette manipulation avec -c 2, etc, en fonction du nombre de cartes que vous avez sur la machine. Vous pourrez ainsi identifier les cartes de la machine.
Maintenant, nous avons installé les bibliothèques et les exécutables. Nous avons aussi configuré les identifiants de noeuds. L'étape d'après est d'effectuer le plan de noms ou d'adresses IP pour les noeuds SCI.
Le fichier de configuration des sockets SCI doit être placé
dans le fichier /etc/sci/scisock.conf. Ce
fichier contient la carte des noms d'hôtes et leur
correspondance avec les noeuds SCI. L'identifiant de noeud SCI
correspond avec un autre via la carte SCI. Ci-dessous, voici un
fichier de configuration très simple :
#host #nodeId alpha 8 beta 12 192.168.10.20 16
Il est aussi possible de limiter cette configuration pour
qu'elle ne s'applique qu'à une sous-partie des ports des
hôtes. Pour cela, une autre configuration est utilisée, et
placée dans /etc/sci/scisock_opt.conf.
#-key -type -values EnablePortsByDefault yes EnablePort tcp 2200 DisablePort tcp 2201 EnablePortRange tcp 2202 2219 DisablePortRange tcp 2220 2231
Maintenant, nous sommes prêts à installer les pilotes. Nous devons installer d'abord les pilotes bas-niveau, puis les pilotes SCI sockets.
shell>cd DIS/sbin/shell>./drv-install add PSB66shell>./scisocket-install add
Si vous voulez, vous pouvez maintenant tester votre installation en appelant le script qui teste tous les noeuds SCI.
shell>cd /opt/DIS/sbin/shell>./status.sh
Si vous rencontrez une erreur et que vous devez changer les fichiers de configuration SCI, alors il faudra utiliser le programme ksocketconfig pour adapter les configurations.
shell>cd /opt/DIS/utilshell>./ksocketconfig -f
Pour vérifier que les sockets SCI sont fonctionnelles, vous
pouvez utiliser le programme latency_bench
qui a besoin d'un composant serveur et d'un client qui se
connecte au serveur, pour tester les délais : l'activation de
SCI est évidente en lisant les délais de latence. Avant
d'utiliser ces programmes, vous devrez configurer la variable
LD_PRELOAD tel que ci-dessous.
To set up a server use the command
shell>cd /opt/DIS/bin/socketshell>./latency_bench -server
Pour exécuter le client, utilisez cette commande :
shell>cd /opt/DIS/bin/socketshell>./latency_bench -client hostname_of_server
Maintenant, la configuration des sockets SCI est complète. Le cluster MySQL est prêt à s'exécuter avec les sockets SCI et le transporteur SCI, documenté dans Section 16.4.4.9, « Définition d'un transporteur SCI dans un cluster ».
La prochaine étape est de lancer le cluster MysQL. Pour activer
l'utilisation des sockets SCI, il est nécessaire de configurer
la variable d'environnement LD_PRELOAD avant de lancer
ndbd, mysqld et
ndb_mgmd. La variable LD_PRELOAD doit pointer
sur la bibliothèque du noyau qui supporte les sockets SCI.
Voici un exemple pour lancer ndbd depuis un
bash :
bash-shell> export LD_PRELOAD=/opt/DIS/lib/libkscisock.so bash-shell> ndbd
Depuis un environnement tcsh, la même chose se fait avec les commandes suivantes :
tcsh-shell> setenv LD_PRELOAD=/opt/DIS/lib/libkscisock.so tcsh-shell> ndbd
Notez bien que le cluster MysQL ne peut utiliser que les variantes du noyau des sockets SCI.
Le processus ndbd dispose de nombreuses
structures simples qui sont utilisées pour accéder aux
données du cluster MySQL. Voici quelques indicateurs de
performances pour mesurer les performances des commandes et les
effets des interconnexions sur les performances.
Il existe 4 méthodes d'accès :
Accès par clé primaireC'est un accès simple à une ligne, via sa clé primaire. Dnas le cas le plus simple, une seule ligne est lue en même temps. Cela signifie que le coût total des messages TCP/IP et des changements de contexte sont pris en charge par celle seule opération. Dans un mode par lots, où les clés primaires sont distribuées par groupe de 32, chaque groupe va partager le coût des messages TCP/IP et les coûts de changement de contexte (si les messages sont destinés à différents noeuds, il faudra construire les messages nécessaires).
Accès par clé uniqueLes accès par clé unique sont très similaires aux accès par clé primaire, hormis le fait qu'ils sont exécutés sous forme de lecture de l'index, suivi par un accès de clé primaire. Cependant, une seule requête est envoyée par le serveur MySQL, et la lecture de l'index est gérée par le processus ndbd. Par conséquent, ces requêtes gagnent à être réalisées en groupe.
Analyse complète de tableLorsqu'aucun index n'existe pour une table, cette dernière est entièrement analysée. C'est une seule requête qui est envoyée au processus ndbd, qui la divise en analyses paralelles dans les noeuds du cluster. Dans les futures versions du cluster, MySQL sera capable de filtrer un peu mieux ces analyses.
Analyse d'intervalle avec un index ordonnéLorsqu'un index ordonné est utilisé, il va faire une analyse de la même manière qu'une analyse de table, mais il ne traitera que les lignes qui sont dans l'intervalle indiqué par la requête. Dans les futures versions, une optimisation spéciale aura lieu pour s'assurer que tous les attributs de l'index qui sont liés incluent les attributs de la clé, pour que seule une partie de l'index soit analysée, et non pas analysée en paralelle.
Pour vérifier les performances de base de ces méthodes d'accès, nous avons développé un jeu de tests. Un des test, testReadPerf, effectue des accès via clé primaire, clé unique, en batch ou non. Les tests mesurent aussi le coût des analyses par intervalles, en effectuant des tests qui retournent une seule ligne, et finalement, des variantes qui utilisent des analyses d'intervalle pour lire des groupes de lignes.
Dans cette manière, il est possible de mesurer le coût d'un accès à une clé, et le coût de l'analyse d'une ligne, puis de mesurer l'impact des médias de communication.
Nous avons exécuté ces tests avec des sockets TCP/IP classiques et des sockets SCI. Les chiffres indiqués ci-dessous correspondent à des petits accès de 20 lignes par accès aux données. La différence entre les accès de série et par groupe diminue d'un facteur de 3-4 lorsque les lignes font 2 ko. Les sockets SCI ne sont pas testées pour les lignes de 2ko. Les tests ont été effectués sur des clusters de 2 noeuds, avec des machines bi-processeurs, équipées de AMD 1900+.
type d'accès: Sockets TCP/IP Sockets SCI Serial pk access: 400 microsecondes 160 microsecondes Batched pk access: 28 microsecondes 22 microsecondes Serial uk access: 500 microsecondes 250 microsecondes Batched uk access: 70 microsecondes 36 microsecondes Indexed eq-bound: 1250 microsecondes 750 microsecondes Index range: 24 microsecondes 12 microsecondes
Nous avons aussi un autre jeu de test pour comparer les performances des sockets SCI, en utilisant le transport SCI ou le transport TCP/IP. Ces tests utilisent des accès par clé primaire, en série, multi-thread ou multi-thread en groupe, simultanément.
Presque tous les tests ont montrés que les sockets SCI sont
100% plus rapides que les sockets TCP/IP. Le transporteur SCI
était plus rapide dans la plupart des cas, comparés aux
sockets SCI. Un cas notable : les multi-threads ont montré que
le transporteur SCI pouvait se comporter de très mauvaise
manière, s'il est utilisé dans le processus
mysqld.
Dans l'ensemble, notre conclusion est que pour les tests de
performances, les sockets SCI ont améliorés la vitesse de 100%
par rapport aux sockets TCP/IP, sauf sauf dans les rares cas où
les performances ne sont pas un problème comme lors des
analyses par filtres qui prennent beaucoup de temps, où lorsque
de très grands groupes de clé primaires sont en jeu. Dans ce
cas, le temps de calcul processeur de ndbd
prend une forte part du temps de calcul.
Utiliser le transporteur SCI au lieu des sockets SCI ne sert
vraiment qu'entre les processus ndbd.
Utiliser le transporteur SCI ne sert que si un processeur peut
être dédié à un processus ndbd, car le
transporteur SCI s'assure que le processus
ndbd ne reste pas inactif. Il est aussi
important de s'assurer que le processus ndbd
a une priorité suffisament haute pour ne pas être rétrogradé
s'il fonctionne durant un long moment (comme cela se fait en
verrouillant les processus sur un processeur en Linux 2.6). Si
c'est possible, alors le processus ndbd
gagnera 10 à 70% de performances, par rapport aux sockets
SCI : les gains les plus importants interviennent lors des
modifications, et probablement sur les analyses paralelles).
Il y a d'autres implémentations de sockets optimisées pour les clusters, indiquées dans différents articles. Elles incluent les sockets optimisées pour Myrinet, Gigabit Ethernet, Infiniband et interfaces VIA. Nous n'avons testé le cluster MySQL qu'avec les sockets SCI, et nous incluons aussi la documentation ci-dessus sur comment configurer les sockets SCI en utilisant une configuration TCP/IP ordinaire sur un cluster MySQL.
In this section, we provide a listing of known limitations in MySQL Cluster releases in the 4.1.x series when compared to features available when using the MyISAM and InnoDB storage engines. Currently there are no plans to address these in coming releases of 4.1; however, we will attempt to supply fixes for these issues in MySQL 5.0 and subsequent releases. If you check the Cluster category in the MySQL bugs database at http://bugs.mysql.com, you can find known bugs which (if marked 4.1) we intend to correct in upcoming releases of MySQL 4.1.
Noncompliance in syntax (resulting in errors when running existing applications):
Not all charsets and collations supported; see Section C.10.6, « MySQL Cluster-4.1.6, 10 octobre 2004 » for a list of those that are supported.
There are no prefix indexes; only entire fields can be indexed.
Text indexes are not supported.
Geometry datatypes (WKT and WKB) are not supported.
Non compliance in limits/behavior (may result in errors when running existing applications):
There is no partial rollback of transactions. A duplicate key or similar error will result in a rollback of the entire transaction.
A number of hard limits exist which are configurable, but available main memory in the cluster sets limits. See the complete list of configuration parameters in Section 16.4.4, « Fichier de configuration ». Most configuration parameters can be upgraded online. These hard limits include:
Database memory size and index memory size (
DataMemoryandIndexMemory, repectively).The maximum number of transactions that can be performed is set using the configuration parameter
MaxNoOfConcurrentOperations. Note that bulk loading,TRUNCATE TABLE, andALTER TABLEare handled as special cases by running multiple transactions, and so are not subject to this limitation.Different limits related to tables and indexes. For example, the maximum number of ordered indexes per table is determined by
MaxNoOfOrderedIndexes.
Database names, table names and attribute names cannot be as long in NDB tables as with other table handlers. Attribute names are truncated to 31 characters, and if not unique after truncation give rise to errors. Database names and table names can total maximum of 122 characters. (That is, the maximum length for an NDB Cluster table name is 122 characters less the number of characters in the name of the database of which that table is a part.)
In MySQL 4.1 and 5.0, all Cluster table rows are of fixed length. This means (for example) that if a table has one or more
VARCHARfields containing only relatively small values, more memory and disk space will be required when using the NDB storage engine than would be for the same table and data using the MyISAM engine. We are working to rectify this issue in MySQL 5.1.The maximum number of metadata objects is limited to 1600, including database tables, system tables, indexes and BLOBs.
The maximum number of attributes per table is limited to 128.
The maximum permitted size of any one row is 8k, not including data stored in BLOB columns.
The maximum number of attributes per key is 32.
Unsupported features (do not cause errors, but are not supported or enforced):
The foreign key construct is ignored, just as it is in MyISAM tables.
Savepoints and rollbacks to savepoints are ignored as in MyISAM.
Performance and limitation-related issues:
The query cache is disabled, since it is not invalidated if an update occurs on a different MySQL server.
There are query performance issues due to sequential access to the NDB storage engine; it is also relatively more expensive to do many range scans than it is with either MyISAM or InnoDB.
The
Records in rangestatistic is not supported, resulting in non-optimal query plans in some cases. EmployUSE INDEXorFORCE INDEXas a workaround.Unique hash indexes created with
USING HASHcannot be used for accessing a table ifNULLis given as part of the key.
Missing features:
The only supported isolation level is
READ_COMMITTED. (InnoDB supportsREAD_COMMITTED,REPEATABLE_READ, andSERIALIZABLE.) See MySQL Cluster Backup Troubleshooting for information on how this can effect backup/restore of Cluster databases.No durable commits on disk. Commits are replicated, but there is no guarantee that logs are flushed to disk on commit.
Problems relating to multiple MySQL servers (not relating to MyISAM or InnoDB):
ALTER TABLEis not fully locking when running multiple MySQL servers (no distributed table lock).MySQL replication will not work correctly off if updates are done on multiple MySQL servers. However, if the database partitioning scheme done at the application level, and no transactions take place across these partitions, then replication can be made to work.
Autodiscovery of databases is not supported for multiple MySQL servers accessing the same MySQL Cluster. However, autodiscovery of tables is supported in such cases. What this means is that after a database named
db_nameis created or imported using one MySQL server, you should issue aCREATE DATABASEstatement on each additional MySQL server that access the same MySQL Cluster. (As of MySQL 5.0.2 you may also usedb_name;CREATE SCHEMA.) Once this has been done for a given MySQL server, that server should be able to detect the database tables without error.db_name;
Issues exclusive to MySQL Cluster (not related to MyISAM or InnoDB):
All machines used in the cluster must have the same architecture; that is, all machines hosting nodes must be either big-endian or little-endian, and you cannot use a mixture of both. For example, you cannot have a management node running on a PPC which directs a storage node that is running on an x86 machine. This restriction does not apply to machines simply running mysql or other clients that may be accessing the cluster's SQL nodes.
It is not possible to make online schema changes such as those accomplished using
ALTER TABLEorCREATE INDEX. (However, you can import or create a table that uses a different storage engine, then convert it to NDB usingALTER TABLE.)tbl_nameENGINE=NDBCLUSTER;Online adding or dropping nodes is not possible (the cluster must be restarted in such cases).
When using multiple management servers one must give nodes explicit IDs in connectstrings since automatic allocation of node IDs does not work across multiple management servers.
When using multiple management servers one must take extreme care to have the same configurations for all management servers. No special checks for this are performed by the cluster.
The maximum number of storage nodes is 48.
The total maximum number of nodes in a MySQL Cluster is 63. This number includes all MySQL Servers (SQL nodes), storage nodes, and management servers.
This listing is intended to be complete with respect to the conditions set forth at the beginning of this section. You can report any discrepancies that you encounter to the MySQL bugs database at http://bugs.mysql.com/. If we do not plan to fix the problem in MySQL 4.1, we will add it to the list above.
Dans cette section, nous allons présenter les modifications de l'implémentation du cluster MySQL dans la version MySQL 5.0 comparé à la version MySQL 4.1. Nous allons aussi discuter de notre plan de développement pour les futures améliorations du cluster MySQL tel que prévu actuellement pour MySQL 5.1.
Dans le passé, nous avons recommandé aux utilisateurs du cluster MySQL de ne pas utiliser la version 5.0 car le cluster MySQL dans les versions 5.0 n'était pas encore totalement testé. Depuis la version 5.0.3-beta, nous avons produit une version de MySQL 5.0 avec des fonctionnalités de cluster comparables à celles de MySQL 4.1. MySQL 4.1 est toujours recommandé en production; cependant, MySQL 5.0 est de bonne qualité, et nous vous encourageons à commencer les tests avec le Cluster et MySQL 5.0 si vous pensez que vous aurez à l'utiliser en production dans le courant de l'année 2005. Il y a relativement peu de modifications entre les implémentations du cluster NDB en MySQL 4.1 et 5.0, ce qui fait que la migration devraient être rapide et sans douleur.
Depuis MySQL 5.0.3-beta, presque toutes les nouvelles fonctionnalités développées pour le cluster MySQL sont maintenant prévues dans la version 5.1. Nous vous donnerons des indications sur les futures fonctionnalités plus loin dans cette section.
MySQL 5.0.3 beta contient de nombreuses fonctionnalités :
Conditions de
Push-Down: une requête telle queSELECT * FROM t1 WHERE non_indexed_attribute = 1;
va utiliser un scan de table complet, et la condition sera évaluée dans chaque noeud du cluster. Par conséquent, il n'est pas nécessaire d'envoyer les lignes à travers le réseau pour qu'elles soient évaluées : on utilise le transport de fonctions, et non pas le transport de données. Pour ce type de requête, la vitesse d'exécution s'améliore d'un facteur de 5 à 10. Notez que ce type de fonctionnalité est actuellement désactivé par défaut, en attente de plus de tests, mais il devrait fonctionner dans la plupart des cas. Cette fonctionnalité peut être activée via la commande
SET engine-condition-pushdown=On;.Autrement, vous pouvez exécuter le serveur mysqld avec cette fonctionnalité active par défaut en lan¸ant le logiciel avec l'option de démarrage
--engine-condition-pushdown.Vous pouvez utiliser
EXPLAINpour savoir si ces conditions sont remplies.Un avantage majeure de cette modification est que les requêtes sont maintenant exécutées en paralelle. Cela signifie que les requêtes effectuées sur des colonnes non-indexées s'exécute 5 à 10 fois, multiplié par le nombre de noeud de stockages, plus vite que précédemment, car plusieurs processeurs sont utilisés en paralelle.
Économie de
IndexMemory: en MySQL 5.0, chaque enregistrement consomme environs 25 octets en mémoire d'index, et chaque index unique utilise 25 octets par ligne en mémoire, en plus de la mémoire nécessaire au stockage dans une table séparée. Ceci est lié au fait qu'il n'y a pas de stockage de la clé primaire dans la mémoire de l'index.Activation du cache de requête pour
MySQL Cluster: voyez Section 5.11, « Cache de requêtes MySQL » pour des informations sur la configuration et l'utilisation du cache de requête.Nouvelles optimisations : une optimisation qui mérite l'attention est que l'interface de lectures en groupe est maintenant utilisée dans certaines requêtes. Par exemple, observez la requête suivante :
SELECT * FROM t1 WHERE
primary_keyIN (1,2,3,4,5,6,7,8,9,10);Cette requête sera exécutée 2 à 3 fois plus vite que dans les versions précédentes du
MySQL Cluster, car les recherches d'index sont envoyées en groupe et non plus de manière unitaire.
Ce qui est présenté ici est basé sur les récents ajouts dans les sources de MySQL 5.1. Il faut noter que tous les développements de la version 5.1 sont sujets à changement sans préavis.
Il y a actuellement quatre fonctionnalités majeures en cours de développement pour MySQL 5.1 :
Intégration du cluster MySQL dans la réplication : cela permettra de faire des modifications de données depuis n'importe quel serveur MySQL dans le cluster, et de voir la réplication gérée par un autre serveur MySQL du cluster.
Support des enregistrements sur disques : les enregistrements sur le disque seront supportés. Les fichiers indexés, y compris les clés primaires seront toujours stockées en mémoire, mais les autres champs seront sur le disque.
Lignes à taille variable : Une colonne définie comme
VARCHAR(255)occupe aujourd'hui 260 octets de stockage, indépendemment de la quantité de données réellemement enregistrée. En MySQL 5.1, seule quantité utile de mémoire sera utilisée. Cela permettra de réduire considérablement les besoins en espace, par un facteur de 5 dans la plupart des cas.Paritionnement paramétrable : les utilisateurs seront capables de définir des partitions basées sur la clé primaire. Le serveur MySQL sera capable d'ignorer certaines partitions à partir des clauses
WHERE. Le paritionnement basé surKEY,HASH,RANGEetLISTsera possible, de même que le sous-paritionnement. Cette fonctionnalité sera aussi possible avec les autres gestionnaires.
What's the difference in using Cluster vs. using replication?
In a replication setup, a master MySQL server updates one or more slaves. Transactions are committed sequentially, and a slow transaction can cause the slave to lag behind the master. This means that if the master fails, it is possible that the slave might not have recorded the last few transactions. If a transaction-safe engine such as InnoDB is being used, then a transaction will either be complete on the slave or not applied at all, but replication does not guarantee that all data on the master and the slave will be consistent at all times. In MySQL Cluster, all storage nodes are kept in synch, and a transaction committed by any one storage node is committed for all storage nodes. In the event of a storage node failure, all remaining storage nodes will remain in a consistent state.
In short, whereas MySQL replication is asynchronous, MySQL Cluster is synchronous.
Do I need to do any special networking to run Cluster? (How do computers in a cluster communicate?)
MySQL Cluster is intended to be used in a high-bandwidth environment, with computers connecting via TCP/IP. Its performance depends directly upon the connection speed between the cluster's computers. The minimum connectivity requirements for Cluster include a typical 100-megabit Ethernet network or the equivalent. We recommend you use gigabit Ethernet whenever available.
The faster SCI protocol is also supported, but requires special hardware. See MySQL Cluster Interconnects for more information about SCI.
How many computers do I need to run a cluster, and why?
A minimum of three computers is required to run a viable cluster. However, the minimum recommended number of computers in a MySQL Cluster is four: one each to run the management and SQL nodes, and two computers to serve as storage nodes. The purpose of the two storage nodes is to provide redundancy; the management node must run on a separate machine in order to guarantee continued arbitration services in the event that one of the storage nodes fails.
What do the different computers do in a cluster?
A MySQL Cluster has both a physical and logical organisation, with computers being the physical elements. The logical or functional elements of a cluster are referred to as nodes, and a computer housing a cluster node is sometimes referred to as a cluster host. Ideally, there will be one node per cluster host, although it is possible to run multiple nodes on a single host. There are three types of nodes, each corresponding to a specific role within the cluster. These are:
management node (MGM node): Provides management services for the cluster as a whole, including startup, shutdown, backups, and configuration data for the other nodes. The management node server is implemented as the application ndb_mgmd; the management client used to control MySQL Cluster via the MGM node is ndb_mgm.
storage node (data node): Stores and replicates data. Storage node functionality is handled by an instance of the NDB storage node process ndbd.
SQL node: This is simply an instance of MySQL Server (mysqld) started with the --ndb-cluster option.
With which operating systems can I use Cluster?
As of MySQL 4.1.10, MySQL Cluster is officially supported on Linux, Mac OS X, and Solaris. We are working to add Cluster support for other platforms, including Windows (Windows support expected in MySQL 5.0), and our goal is eventually to offer Cluster on all platforms for which MySQL itself is supported.
It may be possible to run Cluster processes on other operating systems (including Windows), but Cluster on any but the three mentioned here should be considered alpha software and not for production use.
What are the hardware requirements for running MySQL Cluster?
Cluster should run on any platform for which NDB-enabled binaries are available. Naturally, faster CPUs and more memory will improve performance, and 64-bit CPUs will likely be more effective than 32-bit processors. There must be sufficent memory on machines used for storage nodes to hold each node's share of the database (see How much RAM does Cluster require? for more info). Nodes can communicate via a standard TCP/IP network and hardware. For SCI support, special networking hardware is required.
Since MySQL Cluster uses TCP/IP, does that mean I can run it over the Internet, with one or more nodes in a remote location?
It is important to keep in mind that communications between the nodes in a MySQL Cluster are not secure; they are neither encrypted nor safeguarded by any other protective mechanism. The most secure configuration for a cluster is in a private network behind a firewall, with no direct access to any Cluster data or management nodes from outside.
It is very doubtful in any case that a cluster would perform reliably under such conditions, as MySQL Cluster was designed and implemented with the assumption that it would be run under conditions guaranteeing dedicated high-speed connectivity such as that found in a LAN setting using 100 Mbps or gigabit Ethernet. We neither test nor warrant its performance using anything slower.
Do I have to learn a new programming or query language to use Cluster?
No. While some specialised commands are used to manage and configure the cluster itself, only standard (My)SQL queries and commands are required for:
creating, altering, and dropping tables
inserting, updating, and deleting table data
creating, changing, and dropping primary and unique indexes
configuring and managing SQL nodes (MySQL servers)
How do I find out what an error or warning message means when using Cluster?
There are two ways in which this can be done:
From within the MySQL Monitor, use SHOW ERRORS or SHOW WARNINGS immediately upon being notified of the error or warning condition. These can also be displayed in MySQL Query Browser.
From a system shell prompt, use perror --ndb
error-code.
Is MySQL Cluster transaction-safe? What table types does Cluster support?
Yes. MySQL Cluster is enabled for tables created with the NDB storage engine, which supports transactions. NDB is the only MySQL storage engine which supports clustering.
What does "NDB" mean?
This stands for "Network Database".
Which version(s) of the MySQL software support Cluster? Do I have to compile from source?
Cluster is supported in the MySQL-max binaries from version 4.1.3 onwards. You can determine whether or not your server binary has NDB support using either of the commands
SHOW VARIABLES LIKE 'have_%';orSHOW ENGINES;. (See Section 5.1.2, «mysqld-max, la version étendue du serveurmysqld» for more information.)Linux users, please note that NDB is not included in the RPMs; you should use the binaries supplied as
.tar.gzarchives in the MySQL Downloads area instead. You can also obtain NDB support by compiling the-maxbinaries from source, but it is not necessary to do so simply to use MySQL Cluster.How much RAM do I need? Is it possible to use disk memory at all?
Currently, Cluster is in-memory only. This means that all table data (including indexes) is stored in RAM. Therefore, if your data takes up 1 gigabyte of space and you wish to replicate it once in the cluster, you'll need 2 gigabytes of memory to do so. This in addition to the memory required by the operating system and any applications running on the cluster computers.
You can use the following formula for obtaining a rough estimate of how much RAM is needed for each storage node in the cluster:
(SizeofDatabase * NumberOfReplicas * 1.1 ) / NumberOfStorageNodes
To calculate the memory requirements more exactly requires determining, for each table in the cluster database, the storage space required per row (see Section 11.5, « Capacités des colonnes » for details), and multiplying this by the number of rows. You must also remember to account for any column indexes as follows:
In MySQL 4.1, each primary key or hash index created for an NDBCluster table requires 25 bytes storage, plus the size of the key, per record. In MySQL 5.0, this amount is reduced to 21-25 bytes per record. These indexes use
IndexMemory.Each ordered index requires 10 bytes storage per record, using
DataMemory.Creating a primary key or unique index also creates an ordered index, unless this index is created with
USING HASH. In other words, if created withoutUSING HASH, a primary key or unique index on a Cluster table will take up 35 bytes (plus the size of the key) per record in MySQL 4.1, and 31-35 bytes per record in MySQL 5.0.Note that creating MySQL Cluster tables with
USING HASHfor all primary keys and unique indexes will generally cause table updates to run more quickly. This is due to the fact that less memory is required (since no ordered indexes are created), and that less CPU must be utilised (since fewer indexes must be read and possibly updated).
It is especially important to keep in mind that every MySQL Cluster table must have a primary key, that the NDB storage engine will create a primary key automatically if none is defined, and that this primary key is created without
USING HASH.We often see questions from users who report that, when they're trying to populate a Cluster database, the loading process terminates prematurely and an error message like this one is observed:
ERROR 1114: The table 'my_cluster_table' is full
When this occurs, the cause is very likely to be that your setup does not provide sufficient RAM for all table data and all indexes, including the primary key required by NDB.
It is also worth noting that all storage nodes should have the same amount of RAM, as no storage node in a cluster can use more memory than the least amount available to any individual storage node. In other words, if there are three computers hosting Cluster storage nodes, with two of these having three gigabytes of RAM available to store Cluster data, and one having only one GB RAM, then each storage node can devote only one GB for Cluster.
In the event of a catstrophic failure - say, for instance, the whole city lost power AND my UPS failed - would I lose all my data?
All committed transactions are logged. Therefore, while it is possible that some data could be lost in the event of a catastrophe, this should be quite limited. Data loss can be further reduced by minimising the number of operations per transaction.
Is it possible to use FULLTEXT indexes with Cluster?
FULLTEXTindexing is not currently (MySQL 4.1.9) supported by the NDB storage engine. We are working to add this capability in a future release.Can I run multiple nodes on a single computer?
It is possible but not advisable. One of the chief reasons to run a cluster is to provide redundancy; in order to enjoy the full benefits of this redundancy, each node should reside on a separate machine. If you place multiple nodes on a single machine and that machine fails, you lose all of those nodes. Given that MySQL Cluster can be run on commodity hardware loaded with a low-cost or even no-cost operating system, it is well worth the expense of an extra machine or two in order to safeguard mission-critical data. It also worth noting that the requirements for a cluster host running a management node are minimal; this task can be accomplished with a 200 MHz Pentium CPU and sufficient RAM for the operating system plus a small amount of overhead for the ndb_mgmd and ndb_mgm processes.
Can I add nodes to a cluster without restarting it?
Not at present. A simple restart is all that is required for adding new MGM or SQL nodes to a Cluster. When adding storage nodes the process is more complex and requires the following steps:
Making a complete backup of all Cluster data
Complete shutting down the cluster and all cluster node processes
Restarting the cluster, using the --initial startup option
Restoring all cluster data from the backup
In future, we hope to implement "hot" reconfiguration capability for MySQL Cluster in order to minimize if not eliminate requirements for restarting the cluster when adding new nodes.
Are there any limitations that I should be aware of when using Cluster?
NDB tables in MySQL 4.1 are subject to the following limitations:
Not all character sets and collations are supported. (For a complete listing of those that are supported, see Section C.10.6, « MySQL Cluster-4.1.6, 10 octobre 2004 »).
FULLTEXTindexes and prefix indexes are not supported. Only complete columns may be indexed.Chapitre 18, Données spatiales avec MySQL are not supported.
Only complete rollbacks for transactions are supported. Partial rollbacks and rollbacks to save points are not supported.
The maximum number of attributes allowed per table is 128, and attribute names cannot be any longer than 31 characters. For each table, the maximum combined length of the table and database names is 122 characters.
The maximum size for a table row is 8 kilobytes, not counting BLOBs. There is no set limit for the number of rows per table; table size limits depend on a number of factors, in particular on the amount of RAM available to each data node.
The NDB engine does not support foreign key constraints. As with MyISAM tables, these are ignored.
Query caching is not supported.
We expect to lift many of these restrictions in MySQL 5.0. For additional information on current limitations, see Section 16.8, « Cluster Limitations in MySQL 4.1 ».
How do I import an existing MySQL database into a cluster?
You can import databases into MySQL Cluster much as you would with any other version of MySQL. Other than the limitation mentioned in the previous question, the only other special requirement is that any tables to be included in the cluster must use the NDB storage engine. This means that the tables must be created with the option ENGINE=NDB or ENGINE=NDBCLUSTER.
How do cluster nodes communicate with one another?
Cluster nodes can communicate via any of three different protocols: TCP/IP, SHM (shared memory), and SCI (Scalable Coherent Interface). Where available, SHM is used by default between nodes residing on the same cluster host. SCI is a high-speed (1 gigabit per second and higher), high-availability protocol used in building scalable multi-processor systems; it requires special hardware and drivers. See Section 16.7, « Utilisation d'interconnexions haute vitesse avec MySQL Cluster » for more about using SCI as a transport mechanism in MySQL Cluster.
What is an arbitrator?
If one or more nodes in a cluster fail, it is possible that not all cluster nodes will not be able to "see" one another. In fact, it is possible that two sets of nodes might become isolated from one another in a network partitioning, also known as a "split brain" scenario. This type of situation is undesirable because each set of nodes tries to behave as though it is the entire cluster.
When cluster nodes go down, there are two possibilities. If more than 50% of the remaining nodes can communicate with each other, then we have what is sometimes called a "majority rules" situation, and this set of nodes is considered to be the cluster. The arbitrator comes into play when there is an even number of nodes: in such a case, the set of nodes to which the arbitrator belongs is considered to be the cluster, and nodes not belonging to this set are shut down.
The above is somewhat simplified; a more complete explanation taking into account node groups follows below:
When all nodes in at least one node group are alive, network partitioning is not an issue, because no one portion of the cluster can form a functional cluster. The real problem arises when no single node group has all its nodes alive, in which case network partitioning (the "split-brain" scenario) becomes possible. Then an arbitrator is required. All cluster nodes recognise the same node as the arbitrator, which is normally the management server; however, it is possible to configure any of the MySQL Servers in the cluster to act as the arbirtrator instead. The arbitrator accepts the first set of cluster nodes to contact it, and tells the remaining set to die. Arbitrator selection is controlled by the
ArbitrationRankconfiguration parameter for MySQL Server and management server nodes. (See Section 16.4.4.4, « Définition du serveur de gestion du cluster » for details.) It should also be noted that the role of arbitrator does not in and of itself impose any heavy demands upon the host so designated, and thus the artitrator host does not need to be particularly fast or to have extra memory especially for this purpose.What column types are supported by MySQL Cluster?
MySQL Cluster supports all of the usual MySQL column types, with the exception of those associated with MySQL's Chapitre 18, Données spatiales avec MySQL. In addition, there are some differences with regard to indexes when used with NDB tables. Note: In MySQL 4.1 and 5.0, Cluster tables (that is, tables created with
ENGINE=NDBCLUSTER) have only fixed-width rows. This means that (for example) each record containing aVARCHAR(255)column will will require 256 bytes of storage for that column, regardless of the size of the data stored therein. This issue is expected to be fixed in MySQL 5.1.See Section 16.8, « Cluster Limitations in MySQL 4.1 » for more information about these issues.
How do I start and stop MySQL Cluster?
It is necessary to start each node in the cluster separately, in the following order:
Start the management node with the ndb_mgmd command.
Start each storage node with the ndbd command.
Start each MySQL server (SQL node) using mysqld_safe --user=mysql &.
Each of these commands must be run from a shell on the machine housing the affected node. You can verify the the cluster is running by starting the MGM management client ndb_mgm on the machine housing the MGM node.
What happens to cluster data when the cluster is shut down?
The data held in memory by the cluster's storage nodes is written to disk, and is reloaded in memory the next time that the cluster is started.
To shut down the cluster, enter the following in a shell on the machine hosting the MGM node:
shell>
ndb_mgm -e shutdownThis will cause the ndb_mgm, ndb_mgm, and any ndbd processes to terminate gracefully. MySQL servers running as Cluster SQL nodes can be stopped using mysqladmin shutdown.
For more information, see Section 16.6.1, « Commandes du client de gestion du Cluster » and Section 16.3.6, « Arrêt et redémarrage du cluster ».
Is it helpful to have more than one management node for a cluster?
It can be helpful as a fail-safe. Only one MGM node controls the cluster at any given time, but it is possible to configure one MGM as primary, and one or more additional management nodes to take over in the evnt that the primary MGM node fails.
Can I mix different kinds of hardware and operating systems in a Cluster?
Yes, so long as all machines and operating systems are the same endian. It is also possible to use different MySQL Cluster releases on different nodes (for example, 4.1.8 on some nodes and 4.1.9 on others); however, we recommend this be done only as part of a rolling upgrade procedure.
Can I run two storage nodes on a single host? Two SQL nodes?
Yes, it is possible to do this. In the case of multiple storage nodes, each node must use a different data directory. If you want to run multiple SQL nodes on one machine, then each instance of mysqld must use a different TCP/IP port.
Can I use hostnames with MySQL Cluster?
Yes, it's possible to use DNS and DHCP for cluster hosts. However, if your application requires "five nines" availability, we recommend using fixed IP addresses. This is because making communication between Cluster hosts dependent on such services introduces additional points of failure, and the fewer of these, the better.
The following terms are useful to an understanding of MySQL Cluster or have specialised meanings when used in relation to it.
Cluster: In its generic sense, a cluster is a set of computers functioning as a unit and working together to accomplish a single task. NDB Cluster is the storage engine used by MySQL to implement data storage, retrieval, and management distributed amongst several computers. MySQL Cluster refers to a group of computers working together using the NDB engine to support a distributed MySQL database in a shared-nothing architecture using in-memory storage.
Configuration files: Text files containing directives and information regarding the cluster, its hosts, and its nodes. These are read by the cluster's management nodes when the cluster is started. See Section 16.4.4, « Fichier de configuration » for details.
Backup: A complete copy of all cluster data, transactions and logs, saved to disk or other long-term storage.
Restore: Returning the cluster to a previous state as stored in a backup.
Checkpoint: Generally speaking, when data is saved to disk, it is said that a checkpoint has been reached. More specific to Cluster, it is a point in time where all committed transactions are stored on disk. With regard to the NDB storage engine, there are two sorts of checkpoints which work together to ensure that a consistent view of the cluster's data is maintained:
Local Checkpoint (LCP): This is a checkpoint that is specific to a single node; however, LCP's take place for all nodes in the cluster more or less concurrently. An LCP involves saving all of a node's data to disk, and so usually occurs every few minutes. The precise interval varies, and depends upon the amount of data stored by the node, the level of cluster activity, and other factors.
Global Checkpoint (GCP): A GCP occurs every few seconds, when transactions for all nodes are synchronised and the redo-log is flushed to disk.
Cluster host: A computer making up part of a MySQL Cluster. A cluster has both a physical structure and a logical structure. Physically, the cluster consists of a number of computers, known as cluster hosts (or more simply as hosts). See also Node, Node group.
Node: This refers to a logical or functional unit of MySQL Cluster, sometimes also referred to as a cluster node. In the context of MySQl Cluster, we use the term node to indicate a process rather than a physical component of the cluster. There are three node types required to implement a working MySQL Cluster. These are:
Management (MGM) nodes: Manages the other nodes within the MySQL Cluster. It provides configuration data to the other nodes; starts and stops nodes; handles network partitioning; creates backups and restores from them, and so forth.
SQL (MySQL server) nodes: Instances of MySQL Server which serve as front ends to data kept in the cluster's storage nodes. Clients desiring to store, retrieve, or update data can access an SQL node just as they would any other MySQL Server, employing the usual authentication methods and API's; the underlying distribution of data between node groups is transparent to users and applications. SQL nodes access the cluster's databases as a whole without regard to the data's distribution across different storage nodes or cluster hosts.
Data nodes (also referred to as storage nodes): These nodes store the actual data. Table data fragments are stored in a set of node groups; each node group stores a different subset of the table data. Each of the nodes making up a node group stores a replica of the fragment for which that node group is responsible. Currently a single cluster can support a total of up to 48 data nodes.
It is possible for more than one node to co-exist on a single machine. (In fact, it is even possible to set up a complete cluster on one machine, although one would almost certainly not want to do this in a production environment.) It may be helpful to remember that, when working with MySQL Cluster, host refers to a physical component of the cluster whereas a node is a logical or functional component (that is, a process).
Note Regarding Obsolete Terms: In older versions of the MySQL Cluster documentation, data nodes were sometimes referred to as "Database nodes" or "DB nodes". In addition, SQL nodes were sometimes known as "client nodes" or "API nodes". This older terminology has been deprecated in order to minimize confusion, and for these reasons should be avoided.
Node group: A set of data nodes. All data nodes in a node group contain the same data (fragments), and all nodes in a single group should reside on different hosts. It is possible to control which nodes belong to which node groups.
Node failure: MySQL Cluster is not solely dependent upon the functioning of any single node making up the cluster; the cluster can continue to run if one or more nodes fail. The precise number of node failures that the cluster can tolerate depends upon the number of nodes and the cluster's configuration.
Node restart: The process of restarting a failed cluster node.
Initial node restart: The process of starting a cluster node with its filesystem removed. This is sometimes used in the course of software upgrades and in other special circumstances.
System crash (or system failure): This can occur when so many cluster nodes have failed that the cluster's state can no longer be guaranteed.
System restart: The process of restarting the cluster and reinitialising its state from disk logs and checkpoints. This is required after either a planned or an unplanned shutdown of the cluster.
Fragment: A portion of a database table; in the NDB storage engine, a table is broken up into and stored as a number of fragments. A fragment is sometimes also called a partition; however, "fragment" is the preferred term. Tables are fragmented in MySQL Cluster in order to facilitate load balancing between machines and nodes.
Replica: Under the NDB storage engine, each table fragment has number of replicas stored on other storage nodes in order to provide redundancy. Currently there may be up 4 replicas per fragment.
Transporter: A protocol providing data transfer between nodes. MySQL Cluster currently supports 4 different types of transporter connections: TCP/IP (local), TCP/IP (remote), SCI, and SHM (experimental in MySQL 4.1).
TCP/IP is, of course, the familiar network protocol that underlies HTTP, FTP, etc., on the Internet.
SCI (Scalable Coherent Interface) is a high-speed protocol used in building multiprocessor systems and parallel-processing applications. Use of SCI with MySQL Cluster requires specialised hardware and is discussed in Section 16.7.1, « Configurer le cluster MySQL avec les sockets SCI ». For a basic introduction to SCI, see this essay at dolphinics.com.
SHM stands for Unix-style shared memory segments. Where supported, SHM is used automatically to connect nodes running on the same host. This is experimental in MySQL 4.1, but we intend to enable it fully in MySQL 5.0. The Unix man page for
shmop(2)is a good place to begin obtaining additional information about this topic.
Note: The cluster transporter is internal to the cluster. Applications using MySQL Cluster communicate with SQL nodes just as they do with any other version of MySQL Server (via TCP/IP or Windows named pipes/Unix sockets). Queries can be sent and results retrieved using the standard APIs.
NDB: Refers to the storage engine used to enable MySQL Cluster. The NDB storage engine supports all the usual MySQL column types and SQL statements, and is ACID-compliant. This engine also provides full support for transactions (commits and rollbacks). "NDB" stands for Network Database.
Share-nothing architecture: The ideal architecture for a MySQL Cluster. In a true share-nothing setup, each node runs on a separate host. The advantage such an arrangement is that there no single host or node can act as single point of failure or as a performance bottle neck for the system as a whole.
In-memory storage: All data stored in each data node is kept in memory on the node's host computer. For each data node in the cluster, you must have available an amount of RAM equal to the size of the database times the number of replicas, divided by the number of data nodes. Thus, if the database takes up 1 gigabyte of memory, and you wish to set up the cluster with 4 replicas and 8 data nodes, a minimum of 500 MB memory will be required per node. Note that this is in addition to any requirements for the operating system and any applications running on the host.
Table: As is usual in the context of a relational database, the term "table" denotes an ordered set of identically structured records. In MySQL Cluster, a database table is stored in a data node as a set of fragments, each of which is replicated on additional data nodes. The set of data nodes replicating the same fragment or set of fragments is referred to as a node group.
Cluster programs: These are command-line programs used in running, configuring and administering MySQL Cluster. They include both server daemons:
ndbd: The data node daemon (runs a data node process)ndb_mgmd: The management server daemon (runs a management server process)
and client programs:
ndb_mgm: The management client (provides an interface for executing management commands)ndb_waiter: Used to verify status of all nodes in a clusterndb_restore: Restores cluster data from backup
For more about these programs and their uses, see Section 16.5, « Serveur de gestion du cluster MySQL ».
Event log: MySQL Cluster logs events by category (startup, shutdown, errors, checkpoints, etc.), priority, and severity. A complete listing of all reportable events may be found in Section 16.6.2, « Rapport d'événements générés par le cluster MySQL ». Event logs are of two types:
Cluster log: Keeps a record of all desired reportable events for the cluster as a whole.
Node log: A separate log is also kept for each individual node.
Under normal circumstances, it is necessary and sufficient to keep and examine only the cluster log. The node logs need be comsulted only for application development and debugging purposes.